Cài đặt và cấu hình Hadoop Cluster
Bài viết này sẽ hướng dẫn cách cài đặt và cấu hình Hadoop Cluster.
Hadoop là một dự án Apache mã nguồn mở cho phép tạo các ứng dụng xử lý song song trên các tập dữ liệu lớn, được phân phối trên các nodes được kết nối mạng. Nó bao gồm Hadoop Distributed File System (HDFS™) xử lý khả năng mở rộng và dự phòng dữ liệu giữa các nodes và Hadoop YARN, một khuôn khổ để lập lịch thực hiện các tác vụ xử lý dữ liệu trên tất cả các nodes.
Kiến trúc hadoop cluster
Kiến trúc Hadoop Cluster gồm 2 loại node chính:
- Master node: lưu giữ thông tin về hệ thống file phân tán, tương đương với bảng inode của ext3, ngoài ra còn có nhiệm vụ lên kế hoạch phân bổ tài nguyên. Trong guide này, node master có 2 nhiệm vụ chính:
- Name node: quản lý hệ thống file phân tán, nắm thông tin block dữ liệu nào nằm ở đâu trong cluster.
- ResourceManager: quản lý các job của YARN và quản lý các job được xếp lịch chạy trên các node slave.
- Worker nodes: lưu dữ liệu thực và cung cấp sức mạnh phần cứng để chạy các job, trong lab này là node1 và node2:
- Datanode: quản lý các block dữ liệu về mặt vật lý.
- Nodemanager: quản lý thực hiện các task trên node.
Cài đặt hadoop cluster:
Chuẩn bị:
Với bài hướng dẫn này sẽ được tiến hành cài đặt trên 3 VPS OS Ubuntu 20 LTS hoặc 3 Server OS Ubuntu 20 LTS với IP lần lượt là :
- 10.124.11.53
- 10.124.11.16
- 10.124.11.23
Trong đó VPS có IP 10.124.11.53 sẽ đóng vai trò là master trong cụm cluster.
Phần môi trường cần cài đặt trên 3 máy: java jdk 1.8 trở lên. Nếu như các node chúng ta chưa có cài đặt java jdk chúng ta có thể thực thi lệnh sau:
apt-get update && apt-get upgrade
apt-get install openjdk-8-jdk
Kiểm tra phiên bản java jdk trên 3 node:
Master node:
root@masternode:~# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-8u292-b10-0ubuntu1~20.04-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
Node 1:
root@node1:~# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-8u292-b10-0ubuntu1~20.04-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
Node 2:
root@node2:~# java -version
openjdk version "1.8.0_292"
OpenJDK Runtime Environment (build 1.8.0_292-8u292-b10-0ubuntu1~20.04-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
Cấu hình hệ thống
Tạo file host trên mỗi node
Để mỗi node giao tiếp với nhau bằng tên, chúng ta cần tiến hành chỉnh sửa file /etc/hosts để thêm địa chỉ IP:
10.124.11.53 node-master
10.124.11.16 node1
10.124.11.23 node2
Tạo user hadoop
Chúng ta sẽ tiến hành tạo một user mới trên masternode là “hadoop” để quản lý các permission cho đơn giản.
addgroup hadoopgroupusermod -g hadoopgroup hadoop
Tiến hành chuyển sang user hadoop:
su - hadoop
Tạo keypair xác thực cho user hadoop
Master node sẽ sử dụng giao thức ssh để kết nối tới các node khác và quản lý cluster. Thực hiện:
Log in vào node-master với user hadoop , tạo 1 ssh-key gán cho user hadoop. Sau đó thử ssh bằng user hadoop vào từng node 1, nếu như hỏi password tức là đã thành công:
ssh-keygen -b 4096
Tải xuống và giải nén Hadoop Binaries
Đăng nhập vào node-master với user hadoop, download bộ cài hadoop từ trang chủ:
wget http://apache.cs.utah.edu/hadoop/common/current/hadoop-3.3.1.tar.gz
Giải nén
tar -xvf hadoop-3.3.1.tar.gz
Đổi tên thư mục giải nén thành hadoop cho dễ quản lý
mv hadoop-3.3.1 hadoop
Cấu hình một số biến môi trường
PATH=/home/hadoop/hadoop/bin:/home/hadoop/hadoop/sbin:$PATH
Thêm Hadoop vào PATH của chúng ta cho shell. Thực hiện chỉnh sửa file “.bashrc” và thêm các dòng sau:
export HADOOP_HOME=/home/hadoop/hadoop
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
Cấu hình Master Node
Thiết lập JAVA_HOME
Tìm vị trí cài đặt java, mặc định ở /usr/java/java-8-openjdk-amd64
Có thể tìm bằng cách:
update-alternatives --display java
java - auto mode
link best version is /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
link currently points to /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
link java is /usr/bin/java
slave java.1.gz is /usr/share/man/man1/java.1.gz
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java - priority 1081
slave java.1.gz: /usr/lib/jvm/java-8-openjdk-amd64/jre/man/man1/java.1.gz
Chỉnh sửa file “~/hadoop/etc/hadoop/hadoop-env.sh” và thay thế dòng này:
export JAVA_HOME=${JAVA_HOME}
sang dòng sau:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
Đặt đường dẫn Namenode
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node-master:9000</value>
</property>
</configuration>
Đặt đường dẫn cho HDFS
Chỉnh sửa file hdfs-site.conf để giống với cấu hình sau:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nameNode</value>
</property><property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dataNode</value>
</property><property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Lưu ý: Thuộc tính cuối cùng, dfs.replication cho biết số lần dữ liệu được sao chép trong cluster. Chúng có thể đặt 2 để có tất cả dữ liệu được nhân đôi trên hai node. Không nhập giá trị cao hơn số node thực tế.
Thiết lập Yarn làm Job Scheduler
Chỉnh sửa tệp mapred-site.xml, đặt YARN làm khung mặc định cho các hoạt động MapReduce:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
Cấu hình YARN
Chỉnh sửa fiber-site.xml, chứa các tùy chọn cấu hình cho YARN. Trong trường giá trị cho fiber.resourcemanager.hostname, hãy thay thế bằng địa chỉ IP public của node-master:
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property><property>
<name>yarn.resourcemanager.hostname</name>
<value>IP PUBLIC</value>
</property><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Cấu hình Workers
Các Workers file được sử dụng bởi các tập lệnh khởi động để bắt đầu các daemon cần thiết trên tất cả các node. Chỉnh sửa “~/hadoop/etc/hadoop/worker” để bao gồm cả hai nút:
node1
node2
Cấu hình phân bổ RAM
Việc phân bổ ram có thể làm để những node có ram thấp có thể chạy được. Các giá trị mặc định được thiết kế cho các máy 8GB ram trở lên. Dưới đây là những tuỳ chỉnh cho những node 2GB Ram.
Một Yarn job được chạy với 2 loại:
- Một application manager: chịu trách nhiệm giám sát ứng dụng và phối hợp để phân phối excecutor trong cluster (phân phối xem node nào sẽ thực hiện job).
- Một số executor được tạo bởi application manager chạy các job. Đối với các mapredure job, chúng thực hiện các tiến trình map và redure song song.
- Cả 2 app trên chạy trên slave node. Mỗi slave node chạy một NodeManager dạng deamon, chịu trách nhiệm đối với việc tạo container trên mỗi node. Toàn bộ cluster chịu sự quản lý của ResourceManager, lên kế hoạch phân bổ các container trên toàn bộ slavenode, dựa trên nhu cầu cần thiết cho mỗi action hiện tại.
Cấu hình cho node 2GB RAM
Property Value
yarn.nodemanager.resource.memory-mb 1536
yarn.scheduler.maximum-allocation-mb 1536
yarn.scheduler.minimum-allocation-mb 128
yarn.app.mapreduce.am.resource.mb 512
mapreduce.map.memory.mb 256
mapreduce.reduce.memory.mb 25
Sửa file /home/hadoop/hadoop/etc/hadoop/yarn-site.xml và thêm các dòng sau:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property><property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1536</value>
</property><property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property><property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Sửa file /home/hadoop/hadoop/etc/hadoop/mapred-site.xml và thêm các dòng sau:
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>512</value>
</property><property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property><property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value>
</property>
Nhân bản cấu hình vừa thiết lập tới các slave node
Copy hadoop sang slave node:
cd /home/hadoop/
scp hadoop-*.tar.gz node1:/home/hadoop
scp hadoop-*.tar.gz node2:/home/hadoop
Kết nối tới node1, node2 sử dụng ssh, giải nén 2 gói vừa copy sang:
tar -xzf hadoop-3.3.1.tar.gz
mv hadoop-3.3.1 hadoop
Tiến hành dùng spc tại masternode copy config sang node1 và node 2:
for node in node1 node2; do
scp ~/hadoop/etc/hadoop/* $node:/home/hadoop/hadoop/etc/hadoop/;
done
Format HDFS
HDFS sau khi tạo cũng cần phải được format trước khi sử dụng, tương tự như đối với bất kỳ file system truyền thống nào khác.
Trên node master chúng ta gõ lệnh
Chạy và monitor HDFS
Start và Stop HDFS
Mọi thao tác được thực hiện trên node-master:
start-dfs.sh
jps
53410 SecondaryNameNode
53209 NameNode
53516 Jps
Tại node1 và node2:
jps
929 Jps
903 DataNode
Monitor HDFS cluster
Lấy thông tin về cluster đang chạy bằng lệnh:
hdfs dfsadmin -report
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Lấy các thông tin về các lệnh được hỗ trợ bằng lệnh help
hdfs dfsadmin -help
Ngoài ra còn có thể truy cập trang web quản trị: http://node-master-IP:9870
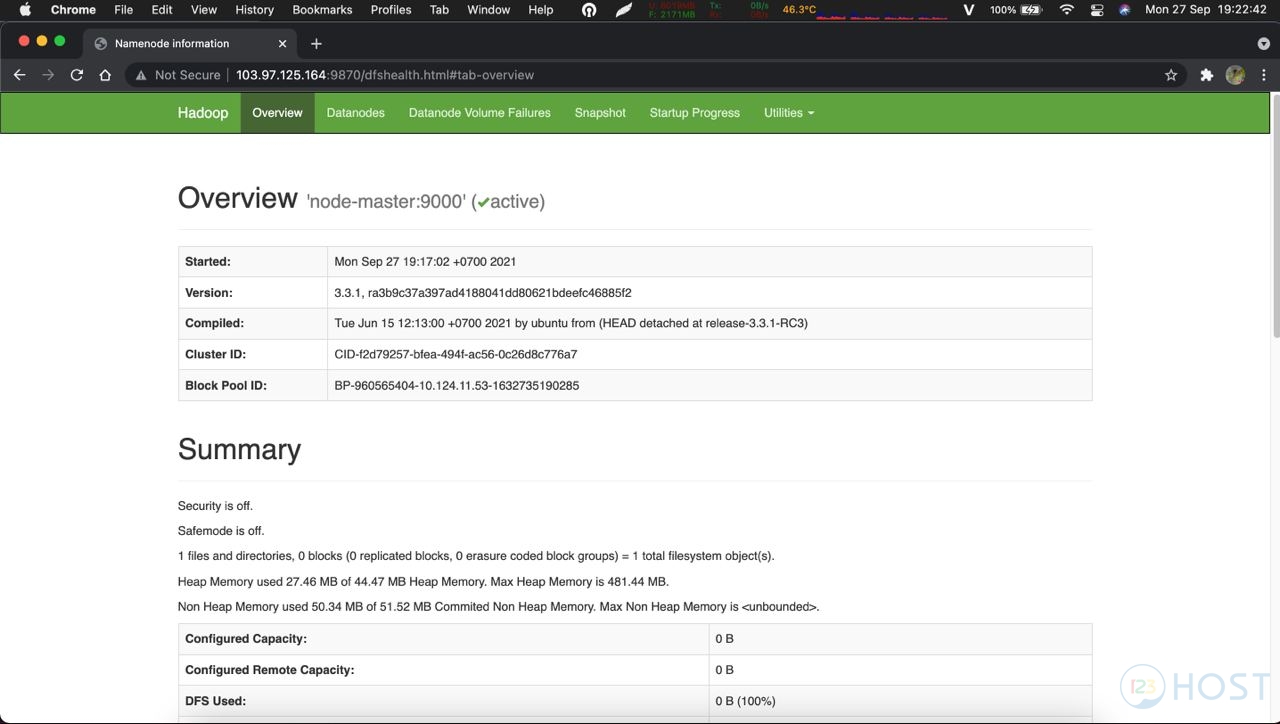
Sử dụng HDFS
Sử dụng lệnh hdfs dfs để thao tác với dữ liệu trên hdfs. Đầu tiên, ta tạo một thư mục mặc định, tất cả các lệnh khác sẽ sử dụng đường dẫn quan hệ tới thư mục home mặc định này.
hdfs dfs -mkdir -p /usr/hadoop/
Tạo thêm thư mục books bên trong hdfs
hdfs dfs -mkdir books
Put dữ liệu lên thư mục books thực hiện lệnh sau:
hdfs dfs -put [data] books
Chúng ta cũng có thể đọc dữ liệu trực tiếp bằng HDFS:
hdfs dfs -cat [duong-dan]
Có nhiều lệnh để quản lý HDFS. Chúng ta có thể xem cách sử dụng hdfs:
hdfs dfs -help
Thực thi YARN
Bắt đầu và dừng yarn
Bắt đầu Yarn với tập lệnh:
start-yarn.sh
Để dừng Yarn, hãy chạy lệnh sau trên node-master:
stop-yarn.sh
Monitor YARN
Chúng cũng có thể in báo cáo về các node đang chạy bằng lệnh:
fiber node -list
Chúng ta có thể nhận được danh sách các ứng dụng đang chạy bằng lệnh:
fiber application -list
Hoặc chúng ta có thể truy cập trình duyệt website với URL để kiểm tra: http://node-master-IP:8088
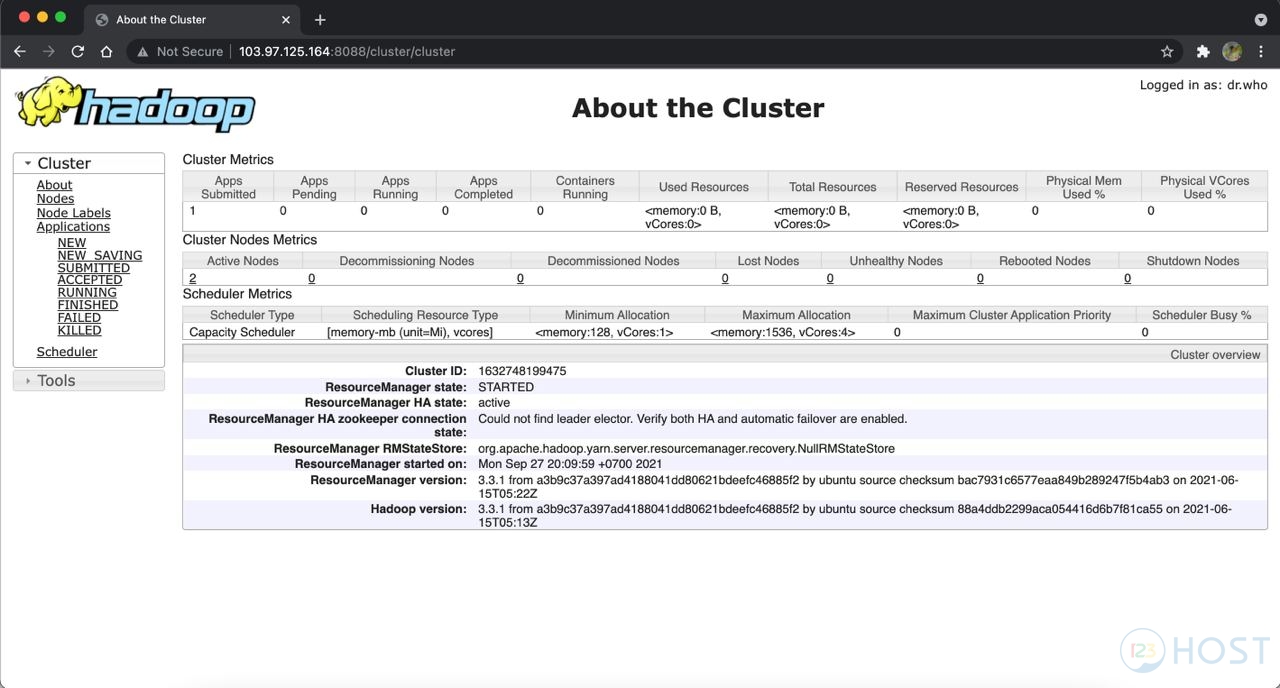
Vậy là đã hoàn thành quá trình hướng dẫn cách cài đặt và cấu hình Hadoop Cluster.
Chúc các bạn thành công!
5
/
5
(
1
vote
)
Related