Hôm nay tôi muốn chia sẻ đến bạn một trong những kỹ thuật tuyệt vời – một phương pháp “SEO hack” hợp pháp mà bạn có thể bắt đầu sử dụng ngay lập tức và cũng không khó để thực hiện.
Đó là robots.txt.
Nó được thiết kế để “làm việc” với các công cụ tìm kiếm, đồng thời robot.txt là cách tăng hiệu quả SEO tự nhiên nhất cho website. Tuy nhiên phương pháp SEO này cũng thuộc hàng “nâng cao nhẹ” và cần sự đầu tư về thời gian.
Hơn nữa nếu phạm sai lầm khi làm robots.txt sẽ có thể gây hại nghiêm trọng cho website. Vì vậy, hãy đảm bảo bạn đã đọc và hiểu toàn bộ bài viết này cũng như SEO là gì trước khi đi sâu vào triển khai nhé.
Bạn đã sẵn sàng? Vậy hãy làm theo tôi. Tôi sẽ chỉ cho bạn chính xác file robot.txt có tác dụng gì và cách tạo file robots.txt chuẩn SEO để các công cụ tìm kiếm yêu thích website và nhanh chóng đạt được mục tiêu nhanh nhất.
Bắt đầu nào!
Tệp Robots.txt là gì?
File robots.txt là file text có dạng .txt, còn được gọi là “Robots Exclusion Standard”. Nó giúp cho các công cụ tìm kiếm biết quy tắc tương tác của website là gì.
Hay bạn có thể hiểu như sau:
Bạn hãy tưởng tượng robots.txt giống như một biển báo “Quy tắc ứng xử” được dán trong phòng tập thể dục, quán bar. Nhưng sẽ có người ý thức “tốt” thì họ tuân theo. Trong khi những người “xấu” có khả năng không tuân theo và bị cấm.
 Robots.txt kiểm soát quá trình thu thập dữ liệu của các công cụ tìm kiếm
Robots.txt kiểm soát quá trình thu thập dữ liệu của các công cụ tìm kiếm
Bot là một chương trình máy tính tự động tương tác với website và ứng dụng. Có bot tốt và bot xấu. Bot tốt được gọi là web crawler bot. Các bot này “crawl” website và index nội dung để hiển thị trong kết quả của công cụ tìm kiếm. Vì vậy, file robots.txt được sinh ra để quản lý hoạt động của các trình thu thập dữ liệu web.
Tại sao bạn phải biết file Robots.txt?
Robots.txt đóng một vai trò thiết yếu trong SEO.
Bạn có thể sử dụng file robots.txt kiểm soát các công cụ tìm kiếm truy cập vào các phần nhất định của website. Không chỉ thế, nó còn giúp bạn ngăn nội dung trùng lặp và cung cấp cho các công cụ tìm kiếm các mẹo hữu ích về cách crawl dữ liệu website hiệu quả hơn.
Ngoài file robot.txt, tôi gợi ý bạn nên tìm hiểu về thẻ Canonical là gì. Một phương pháp ngăn chặn nội dung trùng lặp được nhiều chuyên gia SEO sử dụng.
Cùng tôi xem thử ví dụ dưới đây để hình dung cách file Robots.txt hoạt động nhé:
Ví dụ bạn sở hữu website Thương mại điện tử là https://example.com/ và khách truy cập có thể sử dụng bộ lọc để nhanh chóng tìm kiếm các sản phẩm.
- https://example.com/product?shade=pink
- https://example.com/product?shade=green
Bộ lọc này tạo ra các trang cơ bản hiển thị nội dung giống nhau. Điều này mang lại hiệu quả tốt cho người dùng, nhưng lại gây nhầm lẫn cho các công cụ tìm kiếm vì nó tạo ra nội dung trùng lặp .
Chính vì vậy, bạn không muốn các công cụ tìm kiếm index các trang này. Do đó, bạn thiết lập Disallow để các công cụ tìm kiếm không truy cập các trang sản phẩm được lọc này.
Định dạng cơ bản của Robots.txt
User-agent: [tên user agent - trình thu thập dữ liệu của công cụ tìm kiếm]
Disallow: [URL không được phép thu thập]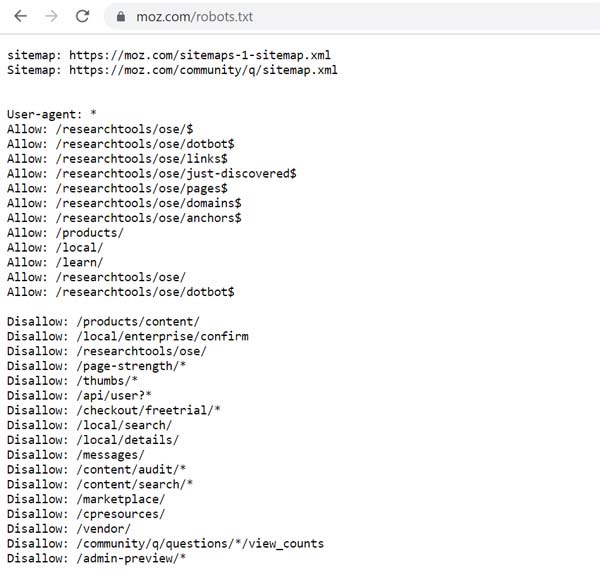 Ví dụ về tạo File Robots.txt cho website Moz.com hoàn chỉnh.
Ví dụ về tạo File Robots.txt cho website Moz.com hoàn chỉnh.
Hai dòng này được coi là một file robots.txt hoàn chỉnh – mặc dù một file robots.txt có thể chứa nhiều user agent và thư mục khác nhau như disallow, allow, crawl-delay, v.v..
Trong file robot.txt, mỗi user-agent xuất hiện theo từng bộ riêng lẻ, được phân biệt bằng dấu ngắt dòng như dưới đây:
User-agent: *
Disallow: /directory1/
User-agent: googlebot
Disallow: /directory2/
User-agent: anothercrawler
Disallow: /Cú pháp phổ biến của file Robots.txt
Các cú pháp robot.txt được xem là ngôn ngữ riêng của tệp robots.txt. Có 5 thuật ngữ phổ biến bạn cần phải biết. Chúng gồm:
User-Agent
Lệnh user-agent cho phép bạn nhắm mục tiêu các bot hoặc trình thu thập dữ liệu nhất định để chỉ đạo. Ví dụ: nếu bạn chỉ muốn nhắm mục tiêu Bing hoặc Google, đây là lệnh bạn sẽ sử dụng.
Mặc dù có hàng trăm user-agent, dưới đây là ví dụ về một số tùy chọn user-agent phổ biến nhất.
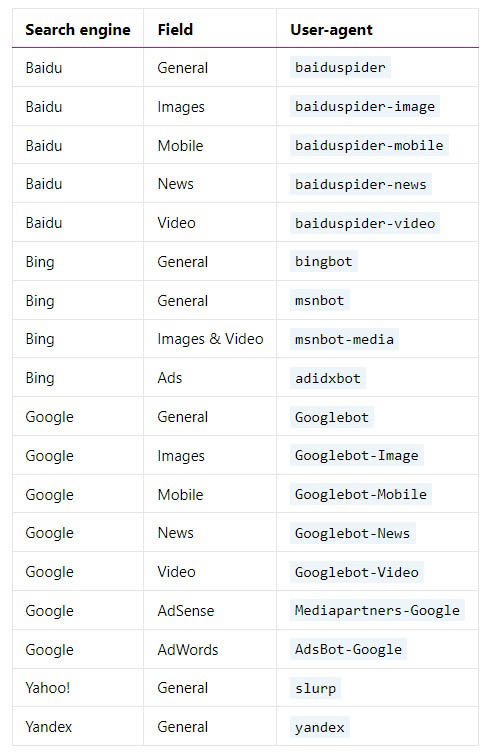 Một số tùy chọn User-Agent phổ biến nhất trong File Robots.txt chuẩn SEO
Một số tùy chọn User-Agent phổ biến nhất trong File Robots.txt chuẩn SEO
Ký tự đại diện User-agent
Ký tự đại diện User-agent được ghi chú bằng dấu hoa thị (*) và cho phép bạn dễ dàng áp dụng chỉ thị cho tất cả các User-agent tồn tại. Vì vậy, nếu bạn muốn một quy tắc cụ thể áp dụng cho mọi bot, bạn có thể sử dụng User-agent này.
User-agent: *
User-agent sẽ chỉ tuân theo các quy tắc áp dụng chặt chẽ nhất cho họ.
Disallow
Lệnh Disallow Robots.txt cho phép yêu cầu các công cụ tìm kiếm không thu thập thông tin hoặc truy cập các trang hoặc thư mục nhất định trên một website.
Bạn có thể xem ví dụ cụ thể dưới đây về cách bạn có thể sử dụng lệnh disallow:
Chặn quyền truy cập vào một thư mục cụ thể
User-agent: *
Disallow: /portfolioAllow
Lệnh Allow giúp xác định các trang hoặc thư mục nào đó mà bạn muốn bots truy cập và crawl.
Trong ví dụ dưới đây, tôi sẽ thông báo với Googlebot rằng tôi không muốn thu thập thông tin thư mục danh mục portfolio, nhưng tôi muốn một mục danh mục portfolio cụ thể được truy cập và thu thập thông tin:
User-agent: Googlebot
Disallow: /portfolio
Allow: /portfolio/crawlableportfolioSitemap
Khi sử dụng lệnh Sitemap, nó sẽ giúp trình thu thập thông tin của công cụ tìm kiếm thu thập thông tin sơ đồ website bạn dễ dàng hơn.
Nếu bạn gửi Sitemap trực tiếp đến các search engine cho từng công cụ tìm kiếm, thì bạn không cần phải thêm nó vào tệp robots.txt của mình.
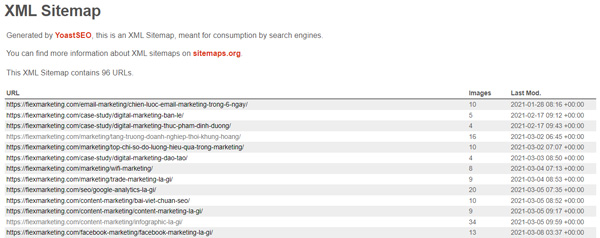 Mẫu sitemap của Fiex Marketing
Mẫu sitemap của Fiex Marketing
Crawl Delay
Đây là chỉ thị bạn nên cẩn thận. Đối với website lớn, nó có thể giảm thiểu số lượng URL được thu thập thông tin mỗi ngày, điều này sẽ phản tác dụng. Tuy nhiên, điều này có thể hữu ích đối với website nhỏ, nơi các bot truy cập nhiều.
Lưu ý: Crawl Delay không được Google hoặc Baidu hỗ trợ. Nếu bạn muốn yêu cầu trình thu thập thông tin của họ làm chậm quá trình thu thập dữ liệu website, bạn cần phải làm điều đó thông qua các công cụ của họ.
Cách sử dụng Biểu thức chính quy và ký tự đại diện
Pattern matching là một cách nâng cao hơn để kiểm soát cách bot thu thập dữ liệu website bằng cách sử dụng các ký tự.
Có hai cách diễn đạt phổ biến và được cả Bing và Google sử dụng. Các chỉ thị này đặc biệt hữu ích trên các website thương mại điện tử.
- Dấu hoa thị: * được coi như một ký tự đại diện và có thể đại diện cho bất kỳ chuỗi ký tự nào
- Ký hiệu đô la: $ được sử dụng để chỉ định phần cuối của một URL
Một ví dụ điển hình về việc sử dụng ký tự đại diện * là trong trường hợp bạn muốn ngăn các công cụ tìm kiếm thu thập thông tin các trang có dấu chấm hỏi trong đó.
Đoạn mã dưới đây yêu cầu tất cả các bot bỏ qua việc thu thập dữ liệu bất kỳ URL nào có dấu chấm hỏi trong đó.
User-agent: *
Disallow: /*?Cách Robots.txt hoạt động như thế nào?
Các công cụ tìm kiếm khám phá và lập chỉ mục web bằng cách thu thập thông tin các trang. Khi thu thập thông tin, họ khám phá và theo dõi các liên kết. Điều này đưa họ từ trang A đến trang B đến trang C…
Nhưng trước khi công cụ tìm kiếm truy cập bất kỳ trang nào trên domain mà chưa từng gặp, nó sẽ mở tệp robots.txt của domain đó.
Điều này, cho phép họ biết những URL nào trên website đó mà họ được phép truy cập (và những URL nào họ không được phép).
Fun Fact: Một số lập trình viên và quản trị viên web lành nghề sử dụng robot.txt để ẩn các tin nhắn thú vị trong trang và gọi đây là “nghệ thuật robot.txt”. Tuy nhiên, “nghệ thuật” này không có tác động đến việc thu thập dữ liệu hoặc tối ưu hóa công cụ tìm kiếm.
File Robots.txt chuẩn SEO nằm ở đâu?
Tệp Robots.txt sẽ luôn nằm ở gốc domain của website.
Ví dụ: tệp của riêng FIEX có thể được tìm thấy tại https://fiexmarketing.com/robots.txt.
Trong hầu hết các website, bạn có thể truy cập để chỉnh sửa tệp đó trong FTP hoặc bằng cách truy cập File Manager trong hosts CPanel.
Nếu bạn đang sử dụng WordPress, file robots.txt có thể được truy cập trong thư mục public_html của website.
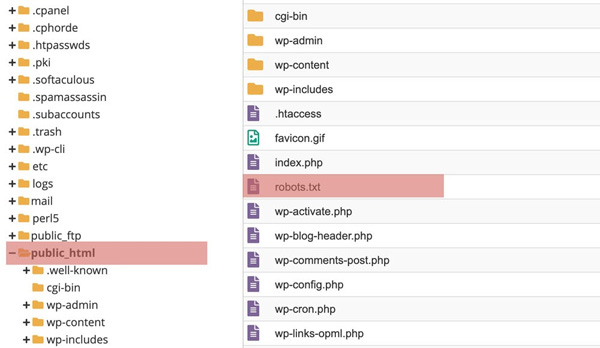 Vị trí của File Robots.txt trong WordPress
Vị trí của File Robots.txt trong WordPress
WordPress bao gồm file robots.txt theo mặc định với cài đặt mới sẽ bao gồm:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Ở trên là yêu cầu các bot thu thập thông tin tất cả các phần của website ngoại trừ bất kỳ thứ gì trong thư mục /wp-admin/ hoặc /wp-include/.
5 bước tạo robot.txt cho website đơn giản nhất
Theo mặc định, WordPress tự động tạo tệp robots.txt ảo cho website. Vì vậy, ngay cả khi bạn không thực hiện gì, thì website đã có file robots.txt mặc định. Bạn có thể kiểm tra xem bằng cách thêm “/robots.txt” vào cuối tên miền của mình.
Ví dụ: “https://fiexmarketing.com/robots.txt” hiển thị tệp robots.txt mà tôi sử dụng tại FIEX:
 Ví dụ mẫu về cách tạo robots.txt của Fiex Marketing
Ví dụ mẫu về cách tạo robots.txt của Fiex Marketing
Tuy nhiên, vì tệp này là ảo nên bạn không thể chỉnh sửa nó. Nếu muốn chỉnh sửa tệp robots.txt của mình, bạn cần thực sự tạo một tệp vật lý trên máy chủ. Dưới đây là ba cách đơn giản để làm điều đó.
Bước 1. Tạo Robots.txt cho WordPress
Tóm Tắt
Cách tạo và chỉnh sửa tệp Robots.txt với Yoast SEO
Nếu đang sử dụng Yoast SEO plugin, bạn có thể tạo (và sau đó chỉnh sửa) tệp robots.txt của mình ngay từ giao diện của Yoast. Tuy nhiên, trước khi có thể truy cập, bạn cần bật các tính năng nâng cao của Yoast SEO bằng cách đi tới SEO → Dashboard → Features và bật tắt trên các trang Cài đặt nâng cao:
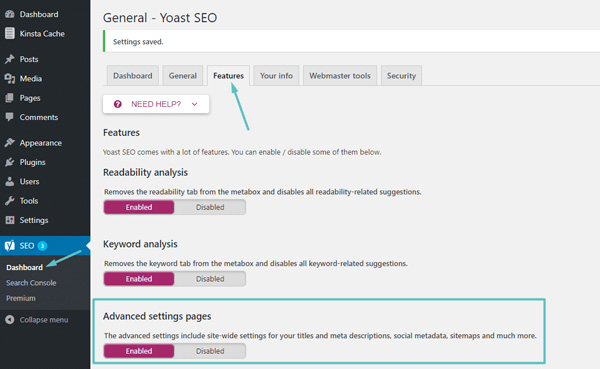 Cách bật các tính năng Yoast nâng cao
Cách bật các tính năng Yoast nâng cao
Sau khi được kích hoạt, bạn đi tới SEO → Tools và click vào File editor:
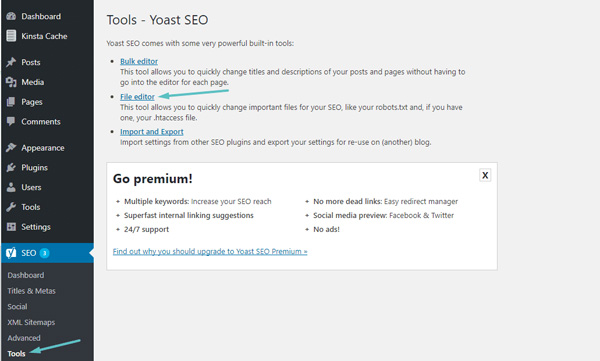 Cách truy cập trình chỉnh sửa tạo File Robots.txt chuẩn trong Yoast SEO
Cách truy cập trình chỉnh sửa tạo File Robots.txt chuẩn trong Yoast SEO
Giả sử bạn chưa có tệp Robots.txt vật lý, Yoast sẽ cung cấp cho bạn tùy chọn Create robots.txt file:
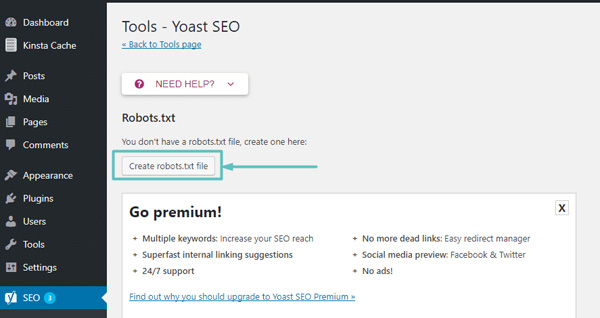 Cách tạo Robots.txt trong Yoast
Cách tạo Robots.txt trong Yoast
Và khi bạn click vào nút đó, bạn sẽ có thể chỉnh sửa nội dung của file Robots.txt của mình trực tiếp từ cùng một giao diện:
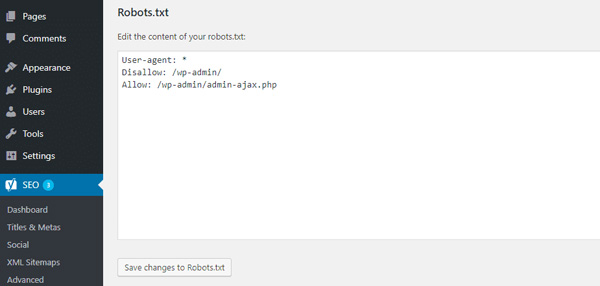 Cách thay đổi Robots.txt tùy chỉnh trong Yoast
Cách thay đổi Robots.txt tùy chỉnh trong Yoast
Tiếp theo, cách thứ hai, tôi sẽ hướng dẫn bạn cách tạo file Robots.txt cho WordPress với All in One SEO Pack.
Cách tạo và chỉnh sửa tệp Robots.txt với All in One SEO Pack
Nếu bạn đang sử dụng plugin All in One SEO Pack, bạn cũng có thể tạo và chỉnh sửa tệp robots.txt WordPress của mình ngay từ giao diện của plugin. Tất cả bạn cần làm là đi đến All in One SEO → Feature Manager và Activate các tính năng Robots.txt:
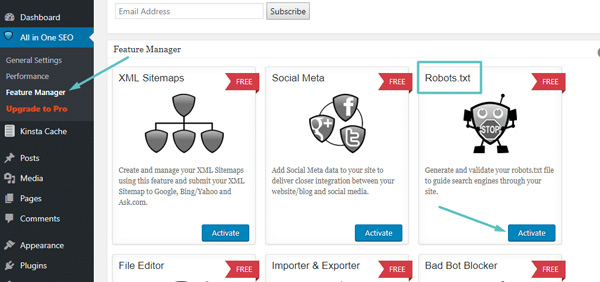 Cách tạo Robots.txt cho website trong All in One SEO Pack
Cách tạo Robots.txt cho website trong All in One SEO Pack
Sau đó, bạn sẽ có thể quản lý file Robots.txt bằng cách đi tới All in One SEO → Robots.txt:
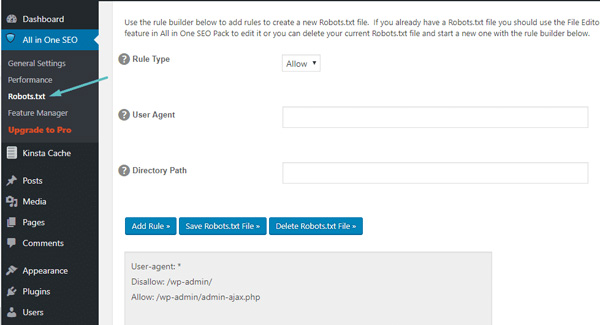 Cách chỉnh sửa Robots.txt trong All in One SEO
Cách chỉnh sửa Robots.txt trong All in One SEO
Cách tạo và chỉnh sửa tệp Robots.txt qua FTP
Nếu không sử dụng plugin SEO cung cấp chức năng robots.txt, bạn vẫn có thể tạo và quản lý tfile robots.txt qua SFTP. Trước tiên, hãy sử dụng bất kỳ trình soạn thảo văn bản nào để tạo một tệp trống có tên “robots.txt”:
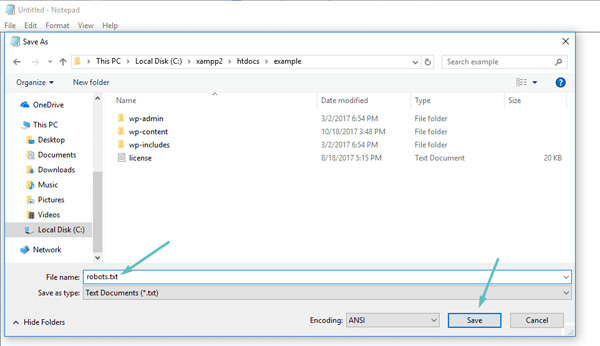 Cách tạo File Robots.txt của riêng bạn qua FTP
Cách tạo File Robots.txt của riêng bạn qua FTP
Sau đó, kết nối với trang web qua SFTP và tải tệp lên thư mục gốc của website. Bạn có thể thực hiện các sửa đổi thêm đối với tệp robots.txt bằng cách chỉnh sửa tệp qua SFTP hoặc tải lên các phiên bản mới của tệp.
Bước 2. Đặt user-agent Robots.txt của bạn
Bước tiếp theo trong cách tạo tệp robots.txt là đặt user-agent.
User-agent hay gọi tắt là UA, là một chuỗi nhận diện của trình duyệt web khi gửi yêu cần đến máy chủ web.
User-agent ở đây tức là trình thu thập thông tin web hoặc công cụ tìm kiếm mà bạn muốn cho phép hoặc chặn. Có ba cách khác nhau để thiết lập user-agent trong tệp robots.txt.
1. Tạo một user-agent
Cú pháp mà bạn sử dụng để đặt user-agent là User-agent. Phần này tôi đã giới thiệu ở trên – phần cú pháp của robots.txt, bạn có thể lưu ảnh trên đó để nghiên cứu nhé.
# Ví dụ về cách đặt user-agent
User-agent: GoogleBot
2. Tạo nhiều hơn một user-agent
Nếu chúng ta phải thêm nhiều hơn một, hãy làm theo quy trình tương tự như bạn đã làm đối với user-agent GoogleBot trên dòng tiếp theo, nhập tên của user-agent bổ sung. Trong ví dụ này, chúng tôi đã sử dụng Facebot.
# Ví dụ về cách đặt nhiều user-agent
- User-agent: GoogleBot
- User-agent: Bingbot
3. Đặt Tất cả Trình thu thập thông tin làm User-agent
Để chặn tất cả bot hoặc trình thu thập thông tin, hãy thay thế tên của bot bằng dấu hoa thị (*).
# Ví dụ về cách đặt tất cả trình thu thập thông tin làm user-agent
User-agent: *
Ghi chú: Dấu thăng (#) biểu thị phần đầu của một nhận xét.
Bước 3. Đặt quy tắc cho tệp Robots.txt của bạn
Tệp robots.txt được đọc theo nhóm. Một nhóm sẽ chỉ định user-agent là ai và có một quy tắc hoặc chỉ thị để cho biết tệp hoặc thư mục nào user-agent có thể hoặc không thể truy cập.
Nhắc lại, dưới đây là các lệnh được sử dụng:
1. Disallow
2. Allow
Cả 2 lệnh này đều có chung 3 đặc điểm sau :
- Nó cũng bắt đầu bằng dấu gạch chéo (/) theo sau là url toàn trang.
- Bạn sẽ chỉ kết thúc nó bằng một dấu gạch chéo nếu nó đề cập đến một thư mục chứ không phải toàn bộ trang.
- Bạn có thể sử dụng một hoặc nhiều cài đặt cho phép cho mỗi quy tắc.
3. Sơ đồ trang web
Trình thu thập dữ liệu web xử lý các lệnh từ trên xuống dưới. Do đó, hãy thêm Disallow: / bên dưới thông tin user-agent trong mỗi nhóm để chặn các user-agent cụ thể ấy thu thập thông tin trang web của bạn.
Một số công thức robots.txt file phổ biến
# Chặn GoogleBot cào website bạn
User-agent: GoogleBot
Disallow: /# Chặn nhiều user-agent (GoogleBot và Bingbot)
User-agent: GoogleBot
User-agent: Bingbot
Disallow: /# Chặn tất cả các trình thu thập thông tin
User-agent: *
Disallow: /# Chặn một miền phụ cụ thể khỏi tất cả các trình thu thập thông tin
Hãy thêm dấu gạch chéo lên phía trước và URL đầy đủ của miền phụ trong quy tắc không cho phép của web. Ví dụ:
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txt# Chặn một thư mục
Hãy làm theo quy trình tương tự bằng cách thêm dấu gạch chéo lên và tên thư mục của bạn, nhưng sau đó kết thúc bằng một dấu gạch chéo chuyển tiếp khác. Ví dụ:
User-agent: *
Disallow: /images/Cuối cùng, nếu bạn muốn tất cả các công cụ tìm kiếm thu thập thông tin trên tất cả các trang trên trang web của mình. Bạn có thể tạo quy tắc allow hoặc disallow, nhưng hãy đảm bảo thêm dấu gạch chéo khi sử dụng quy tắc allow.
Ví dụ về cả hai quy tắc được hiển thị bên dưới.
# Cho phép tất cả các trình thu thập thông tin
User-agent: *
Allow: /# Cho phép tất cả các trình thu thập thông tin
User-agent: *
Disallow:# Chặn quyền truy cập vào một thư mục cụ thể
User-agent: *
Disallow: /portfolio# Chặn PDF hoặc các loại tệp khác
Nếu bạn không muốn tệp PDF hoặc các loại tệp khác của mình được thu thập thông tin, thì lệnh dưới đây sẽ hữu ích.
- Lệnh chặn đối với tệp PDF:
User-agent: *
Disallow: *.pdf$- Đối với tệp PowerPoint, bạn có thể sử dụng:
User-agent: *
Disallow: *.ppt$Bước 4. Tải lên tệp Robots.txt của bạn
Các trang web không tự động đi kèm với tệp robots.txt vì nó không bắt buộc.
Sau khi bạn quyết định tạo một tệp, hãy tải tệp lên thư mục gốc của trang web của bạn. Việc tải lên phụ thuộc vào cấu trúc tệp của trang web và môi trường lưu trữ web của bạn.
Liên hệ với nhà cung cấp hosting để được hỗ trợ về cách tải lên tệp robots.txt nhé.
Bước 5. Xác minh rằng tệp Robots.txt của bạn đang hoạt động tốt
Có một số cách để kiểm tra và đảm bảo rằng tệp robots.txt của bạn hoạt động chính xác. 3 công cụ dưới đây có thể giúp được bạn tìm lỗi cú pháp hoặc logic nhé:
- Trình kiểm tra robots.txt của Google Search Console mà tôi sẽ hướng dẫn ngay sau đây
- Công cụ kiểm tra và xác thực robots.txt của Merkle, Inc.
- Công cụ kiểm tra robots.txt của Ryte.
Nếu bạn đăng ký sử dụng dịch vụ SEO bao gồm cả dịch vụ viết bài cho website của công ty SEO uy tín FIEX Marketing. Chúng tôi sẽ chăm sóc website của bạn từ A-Z, từ yếu tố kỹ thuật nhỏ nhất cho đến lớn nhất. Chỉ sau vài tháng bạn sẽ thấy sự cải thiện rõ rệt trong kết quả kinh doanh.
Cách kiểm tra nhanh website có file robot.txt hay không bằng Google Search Console
Sau khi file robots.txt WordPress được tạo và tải lên, bạn có thể sử dụng Google Search Console để kiểm tra lỗi. Search Console (tên cũ là Google Webmaster Tools) là một tập hợp các chức năng mà Google cung cấp để giúp theo dõi các nội dung xuất hiện trong kết quả tìm kiếm.
Một trong những chức năng này là trình kiểm tra robots.txt, để kiểm tra nhanh website có file robot.txt hay không bằng Google Search Console.
Google Webmaster Tools là gì? Google Webmaster Tools có những chức năng gì giúp bạn SEO tốt hơn? Xem ngay nhé!
Trước tiên, bạn đăng nhập vào bảng điều khiển và điều hướng đến robots.txt Tester tab:
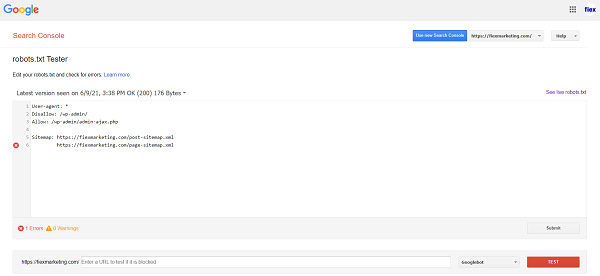 Kiểm tra robot.txt
Kiểm tra robot.txt
Bên trong, bạn sẽ tìm thấy trường trình chỉnh sửa, nơi có thể thêm mã file robots.txt WordPress và click vào nút Submit ngay bên dưới. Google Search Console sẽ hỏi bạn có muốn sử dụng mã mới không hay lấy tệp từ website. Click vào tùy chọn có nội dung Ask Google to Update để gửi theo cách thủ công:
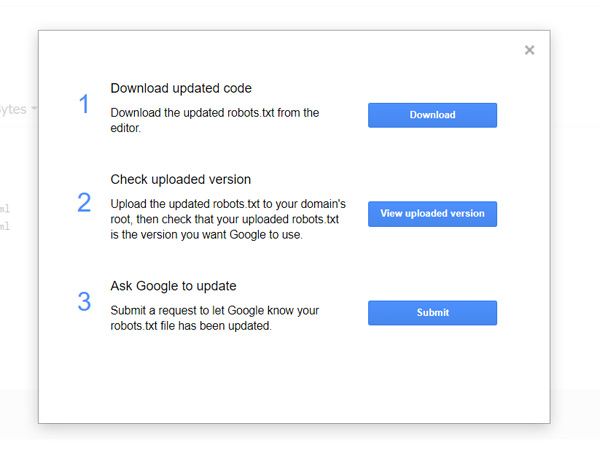 Chọn Ask to Update để gửi
Chọn Ask to Update để gửi
Bây giờ, nền tảng sẽ kiểm tra tệp của bạn để tìm lỗi. Nếu có bất kỳ vấn đề gì nó sẽ chỉ ra cho bạn.
Mẹo nâng cao sử dụng tối ưu file Robots.txt chuẩn SEO
Thứ tự ưu tiên
Điều quan trọng cần lưu ý là các công cụ tìm kiếm xử lý các tệp robots.txt theo cách khác nhau. Theo mặc định, lệnh đầu tiên luôn thắng.
Ví dụ:
User-agent: *
Allow: /about/company/
Disallow: /about/Trong ví dụ trên, tất cả các công cụ tìm kiếm, bao gồm cả Google và Bing không được phép truy cập vào /about/thư mục, ngoại trừ thư mục con /about/company/.
Chỉ một nhóm lệnh cho mỗi robot
Bạn chỉ có thể xác định một nhóm lệnh cho mỗi công cụ tìm kiếm. Việc có nhiều nhóm chỉ thị cho một công cụ tìm kiếm sẽ khiến họ bị rối.
Càng cụ thể càng tốt
Lệnh Disallow này cũng kích hoạt trên các kết quả phù hợp từng phần. Hãy càng cụ thể càng tốt khi xác định Disallow chỉ thị để ngăn việc không cho phép truy cập vào tệp.
Thí dụ:
User-agent: *
Disallow: /directoryChỉ thị cho tất cả robot đồng thời bao gồm chỉ thị cho loại robot cụ thể
Đối với robot, chỉ một nhóm lệnh là hợp lệ. Trong trường hợp các chỉ thị dành cho tất cả các robot tuân theo các chỉ thị dành cho một specific robot, thì chỉ những chỉ thị cụ thể mới được xem xét. Để specific robot cũng tuân theo các chỉ thị cho tất cả rô bốt, bạn cần lặp lại các chỉ thị cho specific robot.
Hãy xem một ví dụ sẽ làm rõ điều này:
Ví dụ
User-agent: *
Disallow: /secret/
Disallow: /test/
Disallow: /not-launched-yet/
User-agent: googlebot
Disallow: /not-launched-yet/File Robots.txt cho (sub)domain
Các lệnh Robots.txt chỉ áp dụng cho (sub)domain mà tệp được lưu trữ trên đó.
Ví dụ
http://example.com/robots.txt là hợp lệ cho http://example.com, nhưng không cho http://www.example.com hoặc https://example.com.
Nguyên tắc xung đột: robots.txt so với Google Search Console
Trong trường hợp file robots.txt của bạn xung đột với cài đặt được xác định trong Google Search Console. Google thường chọn sử dụng cài đặt được xác định trong Google Search Console thay vì các lệnh được xác định trong file robots.txt.
Luôn theo dõi tệp robots.txt
Điều quan trọng là phải theo dõi file robots.txt của bạn để biết các thay đổi. Điều này đúng đặc biệt khi khởi chạy các tính năng mới hoặc một website đã được chuẩn bị thử nghiệm. Vì những tính năng này thường chứa tệp robots.txt sau:
User-agent: *
Disallow: /
Không sử dụng noindex trong robots.txt
Trong nhiều năm, Google đã công khai khuyến cáo không nên sử dụng chỉ thị noindex. Và từ ngày 1 tháng 9 năm 2019, Google đã ngừng hỗ trợ hoàn toàn.
Cách tốt nhất để báo hiệu cho các search engines rằng các page không nên index là sử dụng meta robots tag hoặc X-Robots-Tag..
Ngăn UTF-8 BOM trong tệp robots.txt
Mặc dù Google tuyên bố họ bỏ qua dấu thứ tự byte Unicode tùy chọn ở đầu tệp robots.txt, nhưng tôi khuyên bạn nên ngăn “UTF-8 BOM” vì nó có thể gây ra sự cố với việc giải thích file robots.txt bởi các search engines.
Mẫu file robots.txt khác
Ngoài các mẫu ví dụ ở trên mà tôi đã hướng dẫn, đây là các mẫu file khác giúp bạn có thể chọn ra mẫu robots.txt đang cần.
1. Cho phép tất cả robot truy cập vào mọi thứ:
User-agent: *
Disallow:2. Không cho phép tất cả robot truy cập vào mọi thứ:
User-agent: *
Disallow: /3. Tất cả các bot của Google không có quyền truy cập
User-agent: googlebot
Disallow: /4. Tất cả các bot của Google, ngoại trừ tin tức Googlebot không có quyền truy cập
User-agent: googlebot
Disallow: /
User-agent: googlebot-news
Disallow:5. Googlebot và Slurp không có bất kỳ quyền truy cập nào
User-agent: Slurp
User-agent: googlebot
Disallow: /6. Tất cả các rô bốt không có quyền truy cập vào hai thư mục
User-agent: *
Disallow: /admin/
Disallow: /private/7. Tất cả rô bốt không có quyền truy cập vào một tệp cụ thể
User-agent: *
Disallow: /directory/some-pdf.pdf8. Googlebot không có quyền truy cập vào /admin/ và Slurp không có quyền truy cập vào /private/
User-agent: googlebot
Disallow: /admin/
User-agent: Slurp
Disallow: /private/9. Tệp Robots.txt dành cho WordPress
Tệp robots.txt bên dưới được tối ưu hóa đặc biệt cho WordPress, giả sử:
- Bạn không muốn thu thập thông tin phần quản trị viên.
- Bạn không muốn thu thập thông tin các trang kết quả tìm kiếm nội bộ
- Bạn không muốn thu thập thông tin thẻ và trang tác giả
- Bạn không muốn thu thập thông tin trang 404.
User-agent: *
Disallow: /wp-admin/ #block access to admin section
Disallow: /wp-login.php #block access to admin section
Disallow: /search/ #block access to internal search result pages
Disallow: *?s=* #block access to internal search result pages
Disallow: *?p=* #block access to pages for which permalinks fails
Disallow: *&p=* #block access to pages for which permalinks fails
Disallow: *&preview=* #block access to preview pages
Disallow: /tag/ #block access to tag pages
Disallow: /author/ #block access to author pages
Disallow: /404-error/ #block access to 404 page
Sitemap: https://www.example.com/sitemap_index.xml10. Tệp Robots.txt dành cho Magento
Các tập tin robots.txt dưới đây được tối ưu hóa đặc biệt cho Magento. Nó sẽ làm cho internal search results, login pages, session identifiers và bộ kết quả lọc có chứa price, color, material và size tiêu chí không thể tiếp cận để thu thập.
User-agent: *
Disallow: /catalogsearch/
Disallow: /search/
Disallow: /customer/account/login/
Disallow: /*?SID=
Disallow: /*?PHPSESSID=
Disallow: /*?price=
Disallow: /*&price=
Disallow: /*?color=
Disallow: /*&color=
Disallow: /*?material=
Disallow: /*&material=
Disallow: /*?size=
Disallow: /*&size=
Sitemap: https://www.example.com/sitemap_index.xml
Câu hỏi thường gặp về robots.txt
1. Tệp robots.txt đặt trong thư mục nào?
- Tệp này đặt trong thư mục cao cấp nhất của web nhé. Người mới thường nghĩ tệp robot.txt đặt thư mục nào cũng được nhưng thư mục con không thể chứa robot.txt
2. Nếu tôi muốn chặn Google quét 1 trang bằng lệnh disallow trong robot.txt thì trang đó có “bay màu” khỏi SERPs luôn không?
- Nếu bạn chặn Google quét dữ liệu trên trang có thể khiến trang bị xóa index nhưng không chắc chắn bị xóa khỏi SERPs. Google sẽ dựa trên các yếu tố khác như backlink để quyết định xem trang đó có phù hợp với truy vấn để xuất hiện trên kết quả tìm kiếm hay không.
3. Các thao tác trên tệp robots.txt thì bao lâu mới tạo ra ảnh hưởng thứ hạng của website trên SERPs?
- Trước hết, bộ nhớ đệm của tệp robots.txt phải được làm sạch trước. Ngay cả sau khi tìm thấy nội dung được thay đổi thì thu thập data và index cũng vẫn là một quá trình phức tạp mà chúng ta không thể đưa ra thời gian chính xác.
- Nếu bạn thật sự muốn xóa trang khỏi Google nhanh chóng nhất có thể. Hãy gửi một yêu cầu xóa qua Google Search Console.
4. Tôi có thể ngăn cào dữ liệu trên toàn bộ trang web không?
- Tất nhiên. Bạn có thể làm điều này bằng cách nhập mã HTTP 503 cho tất cả các URL, bao gồm cả tệp robots.txt. Các bot vẫn sẽ vào cào trang từ từ cho đến khi thành công.
5. Lệnh trong tệp robots.txt có phân biệt chữ hoa chữ thường không?
Tất nhiên là có. Nếu máy chủ bạn không phân biệt chữ hoa – chữ thường, bạn nên đảm bảo rằng chỉ có một phiên bản URL được index. Nếu không khả thi, hãy liệt kê tất cả các tổ hợp phổ biến của URL hoặc thư mục và rút ngắn tối đa, dễ hiểu là được.
Lời kết
Để tăng khả năng hiển thị website, bạn cần đảm bảo rằng các bot của Search Engine đang thu thập thông tin liên quan nhất.
Như chúng ta đã thấy, tệp robots.txt WordPress được định cấu hình tốt sẽ cho phép bạn ra lệnh chính xác cách các bot đó tương tác với website. Bằng cách đó, họ sẽ có thể giới thiệu cho người tìm kiếm nội dung hữu ích và phù hợp hơn.
Để SEO đạt hiệu quả cao, bạn không chỉ cần quan tâm file Robots.txt mà cần đảm bảo các checklist thiết kế web chuẩn SEO giá rẻ mà FIEX liệt kê ở đây. Cũng như tìm hiểu vấn đề check Google Sandbox – Một thuật toán “kìm hãm” áp dụng cho các trang web mới.
Bạn đang muốn các từ khóa cạnh tranh đạt thứ hạng cao? Bạn muốn tiếp cận khách hàng tiềm năng và bán được hàng? Đừng ngần ngại liên hệ với công ty Marketing Online TPHCM FIEX.
Chúng tôi không chỉ cam kết SEO lên TOP từ khóa mà còn đưa ra giải pháp Marketing toàn diện giúp tăng trưởng doanh số theo từng tháng. Liên hệ ngay với FIEX Marketing!