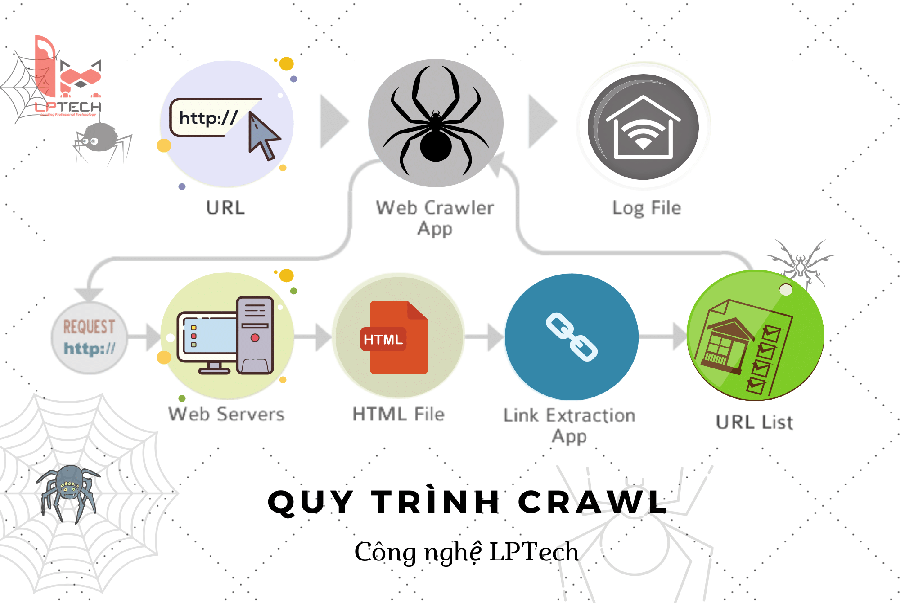
Tóm Tắt
Crawl dữ liệu là gì?
Crawl dữ liệu hay còn gọi là cào dữ liệu là một thuật ngữ không có gì là xa lạ trong ngành marketing, Dịch vụ seo. Vì crawl là kỹ thuật mà các robots của các công cụ tìm kiếm phổ biến hiện nay sử dụng như Google, Yahoo, Bing, Yandex, Baidu… Crawler có công việc chính là thu thập dữ liệu từ một trang web bất kì, hoặc chỉ định trước rồi phân tích cú pháp mã nguồn HTML để đọc dữ liệu và bóc tách thông tin dữ liệu theo yêu cầu mà người dùng đặt ra hoặc các dữ liệu mà Search Engine yêu cầu.
Vậy việc bạn cần crawl dữ liệu của 1 hoặc nhiều wbesite khác cũng tương tự như cách mà Google hay làm. Crawl và sau đó Indexing dữ liệu cào được vào dữ liệu của Google sau cùng là phục vụ cho việc tìm kiếm của chúng ta.
Vậy tại sao bạn cần công cụ crawler nhỉ nghe như là 1 điều to lớn cho những ông lớn sử dụng chứ bạn không cần đúng không? Sai bạn ạ, Thời đại hiện tại là thời đại của công nghệ 4.0 và Big-Data cho nên bạn càng làm chủ DATA bao nhiêu thì bạn càng có nhiều cơ hội hơn trong việc thương mại của doanh nghiệp của bạn hoặc cho cá nhân bạn vào một ứng dụng nào đó.
Bạn đang đọc: Dịch vụ lập trình công cụ crawl dữ liệu website tự động
Crawler phù hợp với những doanh nghiệp nào?
- Sàn TMĐT, Website rao vặt.
- Tin tức hằng ngày.
- Pháp luật đời sống.
- Website vệ tinh – PBN.
- Website bán hàng Online, Nhập hàng nước ngoài.
Ngoài ra việc tăng trưởng 1 công cụ crawl dữ liệu cũng tốn một chút ít ngân sách, vì vậy việc này cũng cần công ty của bạn có năng lượng kinh tế tài chính ổn, xem thêm ở phần ngân sách .
Lợi ích của việc crawler data là gì?
Crawler Data làm giảm tải việc làm phát minh sáng tạo cho nhân viên cấp dưới content của bạn, nhân sự là bài toán vô cùng quan trọng của 1 doanh nghiệp đang khởi nghiệp Online. Bạn nghỉ sao khi vào 1 website mà website chỉ có vài mẫu sản phẩm, hoặc 1 web đọc tin tức mà chỉ có vài tin rất ít ?Bạn sẽ thoát và tìm 1 website giàu nội dung hơn đúng không ? chắc như đinh rồi vì ta chẳn có gì để xem ở 1 website rổng cả. Bạn không đủ kinh tế tài chính để thuê 1 đội nhập liệu vài trăm nhân sự ? Quá cồng kềnh và tốn nhiều ngân sách và thủ tục pháp lý đi kèm cho nhân sự không hề đơn thuần .Nhưng ngược lại nếu bạn góp vốn đầu tư 1 ứng dụng crawler data tự động hóa thì bạn hoàn toàn có thể giảm tải gần như 90 % nhân sự content hiện tại, chỉ giữ 10 % nhân sự để chỉnh sửa, viết lách các nội dung quan trọng cho công ty và quản trị công cụ crawler data mà thôi .
Ngoài ra bạn có có thể sử dụng DATA vào nhiều mục đích khác nhau, như phân tích thị trường, thiết kế website cổng thông tin, thiết kế website rao vặt …. đều được cả, và phù hợp nhất vẫn là thiết kế website bất động sản hoặc mua giới bds vì ngành nghề này rất khát thông tin.

Crawler data sẽ giúp website của bạn có nhiều nội dung hơn, nhiều tin tức hơn .., và sẽ có nhiều Users ( Khách hàng ) hơn .
Bật mí bí mật:
Các công ty chuyên bán hàng Bằng Affiliate (Tiếp thị liên kết) thì việc cần 1 công cụ crawl link, crawl data là vô cùng quan trọng, bạn chỉ cần crawler hết data của các sản phẩm ở website khác, sau đó gắn Link ?Ref=Code (Refer) để có thể tăng doanh số của mình 1 cách chóng mặt.
Công nghệ sử dụng là gì?
LPTech sử dụng các công cụ mới nhất hiện nay để crawl và bóc tách dữ liệu 1 cách chính xác và thông minh. Các ngôn ngữ lập trình crawler tốt nhất hiện tại như:
- Python
- PHP
- Node
Proxy trong crawl là điều vô cùng quan trọng chống các website Victim chặn việc tích lũy của tất cả chúng ta, ngoài những còn có các kỹ thuật khác sử dụng AI để nghiên cứu và phân tích các website hạng sang và có cấu trúc biến hóa liên tục như Zalo Shop, Tiki, Sendo, Chotot, Muaban …
Có bị Google phạt không ?
Về việc crawl data có bị phạt không thì cũng là 1 yếu tố gặp phải của các công ty ứng dụng cung ứng dịch vụ này. Theo nguyên tắc thì việc crawl dữ liệu LPTech sẽ chia làm 2 góc nhìn như sau :
Đối với Google:
Việc copy hay crawl là sẽ tạo ra 1 bản sao chép website đó về Database của bạn nếu bạn chỉ crawler 100% nội dung thì có thể bạn sẽ vi phạm chính sác nội dung của Google và DMCA sẽ khởi kiện bạn, Tuy nhiêu đây không phải là việc quá khó qiải quyết vì công cụ của LPTech cung cấp đủ thông minh để Xử lý dữ liệu 1 lần trước khi crawl về nhằm tránh trùm lắp nội dung.
Hãy lưu ý việc này nếu bạn đang crawl hay copy bằng tay website, bài viết của 1 ai đó thì hãy dừng lại ngay vì bạn sẽ bị thuật toán của GOOGLE chặn sớm thôi. Hãy sử dụng công cụ đủ thông minh tái biên soạn lại nội dung của bạn như LPTech nhé. AI của LPTech sẽ giúp bạn xử lý việc này 1 cách nhanh gọn và an toàn.
Đối với pháp luật VIỆT NAM:
Việt nam có luật bản quyền tác giả được công bố tại Nghị định 22/2018/NĐ-CP quy định chi tiết Luật Sở hữu trí tuệ, Luật sửa đổi Luật Sở hữu trí tuệ về quyền tác giả, quyền liên quan.
Ngoài ra khi bạn là công ty hay cá nhân có nhu cầu crawl dữ liệu thì trước tiện bạn sẽ được kỹ 1 thỏa thuận về bảo mật thông tin (NDA – Non-disclosure agreement) để đảm bảo quyền lợi cho đôi bên.
Quyền tác giả hay tác quyền hoặc bản quyền là độc quyền của một tác giả cho tác phẩm của người này. Quyền tác giả được dùng để bảo vệ các sáng tạo tinh thần có tính chất văn hóa (cũng còn được gọi là tác phẩm) không bị vi phạm bản quyền, ví dụ như các bài viết về khoa học hay văn học, sáng tác nhạc, ghi âm, tranh vẽ, hình chụp, phim và các chương trình truyền thanh. Quyền này bảo vệ các quyền lợi cá nhân và lợi ích kinh tế của tác giả trong mối liên quan với tác phẩm này. Một phần người ta cũng nói đó là sở hữu trí tuệ (intellectual property) và vì thế là đặt việc bảo vệ sở hữu vật chất và sở hữu trí tuệ song đôi với nhau, thế nhưng khái niệm này đang được tranh cãi gay gắt. Quyền tác giả không cần phải đăng ký và thuộc về tác giả khi một tác phẩm được ghi giữ lại ít nhất là một lần trên một phương tiện lưu trữ. Quyền tác giả thông thường chỉ được công nhận khi sáng tạo này mới, có một phần công lao của tác giả và có thể chỉ ra được là có tính chất duy nhất.
Do đó việc copy dữ liệu của 1 website, hay 1 báo điện tử là vi phạm pháp lý ở Việt nam nếu không được đơn vị chức năng chủ quyền lãnh thổ được cho phép. Vì thế việc crawler dữ liệu phải thận trọng trong việc này để tránh vi phạm luật ở VN. Công cụ Crawler của LPTech sẽ copy và đổi khác nội dung gốc để hoàn toàn có thể tránh vi phạm, ngoài những LPTech khuyến nghị nếu bạn cần crawl web tin tức thì nên xin phép của báo đó, hãy liên hệ LPTech để được tư vấn không lấy phí nhé .
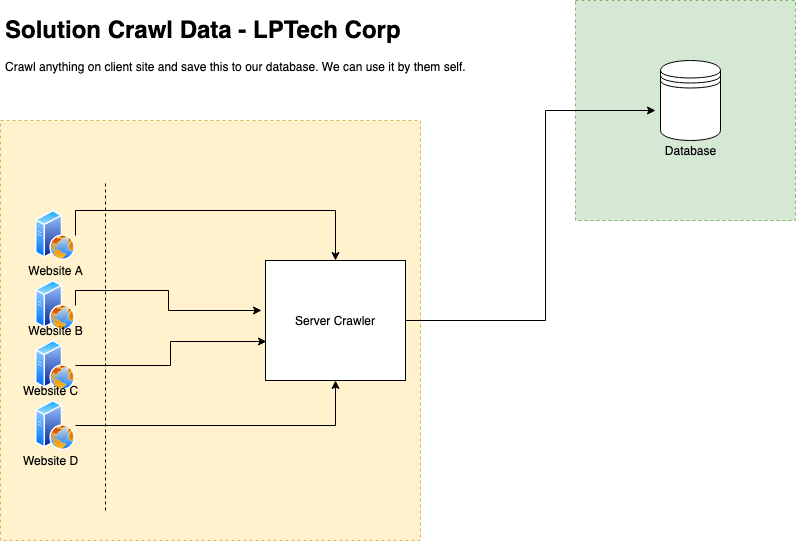
Nếu bạn crawl dữ liệu các website rao vặt thì thường các website này được cho phép việc crawler nên bạn không phải lo nhiều về yếu tố trên .
Kết luận:
Việc crawl dữ liệu để website. ứng dụng của bạn có càng nhiều thông tin hưu ích càng quan trọng vì việc đó càng tăng khả năng tiếp cận của bạn đến mọi người trên Internet. Tất cả các doanh nghiệp lớn làm TMĐT, rao vặt như Muaban, Chotot, muabannhanh … đều có hệ thống crawl data của họ cả. Vì càng có nhiều content thì bạn càng làm chủ vì Content IS King. Có rất nhiều công dụng hữu ích đã nêu trên không phải ai cũng nói cho bạn nghe bí mật như LPTech đã chia sẻ. Hãy liên hệ với LPTech ngay hôm nay để có thể tiếp cận công nghệ đỉnh cao trong thời đại Bigdata hiện nay. Hãy nhớ rằng “Bạn không khác biệt – Bạn thất bại“. Tạo khác biệt của bạn ngay hôm nay với dịch vụ phần mềm crawler data website tự động.

Source: https://final-blade.com
Category: Kiến thức Internet