Các mạng lưới hệ thống đang thao tác với lượng tài liệu khổng lồ tính bằng petabyte hoặc thậm chí còn nhiều hơn và nó vẫn đang tăng trưởng với vận tốc theo cấp số nhân. Dữ liệu lớn hiện hữu ở khắp mọi nơi xung quanh tất cả chúng ta và đến từ những nguồn khác nhau như những website tiếp thị quảng cáo xã hội, bán hàng, tài liệu người mua, tài liệu thanh toán giao dịch, v.v. Và tôi tin chắc rằng, tài liệu này chỉ giữ nguyên giá trị nếu tất cả chúng ta hoàn toàn có thể giải quyết và xử lý nó cả tương tác và nhanh hơn .
Apache Spark là một hệ thống điện toán cụm mã nguồn mở, nhanh chóng và là một khuôn khổ rất phổ biến để phân tích dữ liệu lớn. Khung này xử lý dữ liệu song song giúp tăng hiệu suất. Nó được viết bằng Scala một ngôn ngữ cấp cao và cũng hỗ trợ các API cho Python, SQL, Java và R.
Tóm Tắt
Azure Databricks là gì và nó có liên quan như thế nào đến Spark?
Nói một cách đơn thuần, Databricks là việc tiến hành Apache Spark trên Azure. Với những cụm Spark được quản trị trọn vẹn, nó được sử dụng để giải quyết và xử lý khối lượng việc làm lớn của tài liệu và cũng tương hỗ trong kỹ thuật tài liệu, tò mò tài liệu và cũng như trực quan hóa dữ liệu bằng Máy học .
Trong khi thao tác trên cơ sở tài liệu, tôi thấy nền tảng nghiên cứu và phân tích này cực kỳ thân thiện với nhà tăng trưởng và linh động, dễ sử dụng những API như Python, R, v.v. Để lý giải thêm một chút ít về điều này, giả sử bạn đã tạo một khung tài liệu bằng Python, với Azure Databricks, bạn hoàn toàn có thể tải tài liệu này vào dạng xem trong thời điểm tạm thời và hoàn toàn có thể sử dụng Scala, R hoặc SQL với con trỏ tham chiếu đến dạng xem trong thời điểm tạm thời này. Điều này được cho phép bạn viết mã bằng nhiều ngôn từ trong cùng một sổ ghi chép. Đây chỉ là một trong những tính năng mê hoặc của nó .
Tại sao nên sử dụng Azure Databricks?
Rõ ràng là việc vận dụng Databricks ngày càng trở nên quan trọng và tương thích trong quốc tế tài liệu lớn vì một vài nguyên do. Ngoài tương hỗ nhiều ngôn từ, dịch vụ này cho phép tích hợp thuận tiện với nhiều dịch vụ Azure như Blob Storage, Data Lake Store, SQL Database và những công cụ BI như Power BI, Tableau, v.v. Đây là một nền tảng hợp tác tuyệt vời được cho phép những chuyên viên tài liệu san sẻ những cụm và khoảng trống thao tác, dẫn đến hiệu suất cao hơn .
Dàn ý
Trước khi tất cả chúng ta khởi đầu đào Databricks trong Azure, tôi muốn dành một phút ở đây để diễn đạt cách cấu trúc của loạt bài viết này. Tôi dự tính sẽ trình diễn những góc nhìn sau của Databricks trong Azure trong loạt bài này. Xin quan tâm – dàn ý này hoàn toàn có thể khác nhau ở chỗ này và chỗ khác khi tôi thực sự mở màn viết về chúng .
- Cách truy cập Azure Blob Storage từ Azure Databricks
- Xử lý và khám phá dữ liệu trong Azure Databricks
- Kết nối Cơ sở dữ liệu Azure SQL với Cơ sở dữ liệu Azure
- Tải dữ liệu vào Kho dữ liệu Azure SQL bằng Azure Databricks
- Tích hợp Azure Databricks với Power BI
- Chạy Azure Databricks Notebook trong Azure Data Factory và nhiều hơn nữa…
Trong bài viết này, tất cả chúng ta sẽ nói về những thành phần của Databricks trong Azure và sẽ tạo một dịch vụ Databricks trong Azure portal. Tiếp đó, tất cả chúng ta sẽ tạo một cụm Spark trong dịch vụ này, tiếp theo là tạo một sổ ghi chép trong cụm Spark .
Ảnh chụp màn hình hiển thị dưới đây là sơ đồ do Microsoft đưa ra để lý giải những thành phần Databricks trên Azure :

Có một số ít tính năng đáng đề cập ở đây :
- Databricks Workspace – Nó cung cấp một không gian làm việc tương tác cho phép các nhà khoa học dữ liệu, kỹ sư dữ liệu và các doanh nghiệp cộng tác và làm việc chặt chẽ với nhau trên sổ ghi chép và trang tổng quan
- Databricks Runtime – Bao gồm Apache Spark, chúng là một tập hợp các thành phần và bản cập nhật bổ sung đảm bảo cải tiến về hiệu suất và bảo mật cho khối lượng công việc và phân tích dữ liệu lớn. Các phiên bản này được phát hành một cách thường xuyên
- Như đã đề cập trước đó, nó tích hợp sâu với các dịch vụ khác như dịch vụ Azure, Apache Kafka và Hadoop Storage và bạn có thể xuất bản thêm dữ liệu vào học máy, phân tích luồng, Power BI, v.v.
- Vì nó là một dịch vụ được quản lý hoàn toàn, các tài nguyên khác nhau như bộ nhớ, mạng ảo, v.v. được triển khai cho một nhóm tài nguyên bị khóa. Bạn cũng có thể triển khai dịch vụ này trong mạng ảo của riêng mình. Chúng ta sẽ xem điều này ở phần sau của bài viết
- Databricks File System (DBFS) – Đây là một lớp trừu tượng trên đầu trang của đối tượng lưu trữ. Điều này cho phép bạn gắn kết các đối tượng lưu trữ như Azure Blob Storage cho phép bạn truy cập dữ liệu như thể chúng ở trên hệ thống tệp cục bộ. Tôi sẽ trình bày chi tiết điều này trong bài viết tiếp theo của loạt bài này
Bây giờ tất cả chúng ta đã có hiểu biết triết lý về Databricks và những tính năng của nó, hãy đi đến cổng Azure và xem phương pháp nó hoạt động giải trí .
Tạo dịch vụ Azure Databricks
Giống như bất kỳ tài nguyên nào khác trên Azure, bạn sẽ cần ĐK Azure để tạo Databricks. Trong trường hợp bạn không có, bạn hoàn toàn có thể va đây để tạo một cái không tính tiền cho chính bạn .
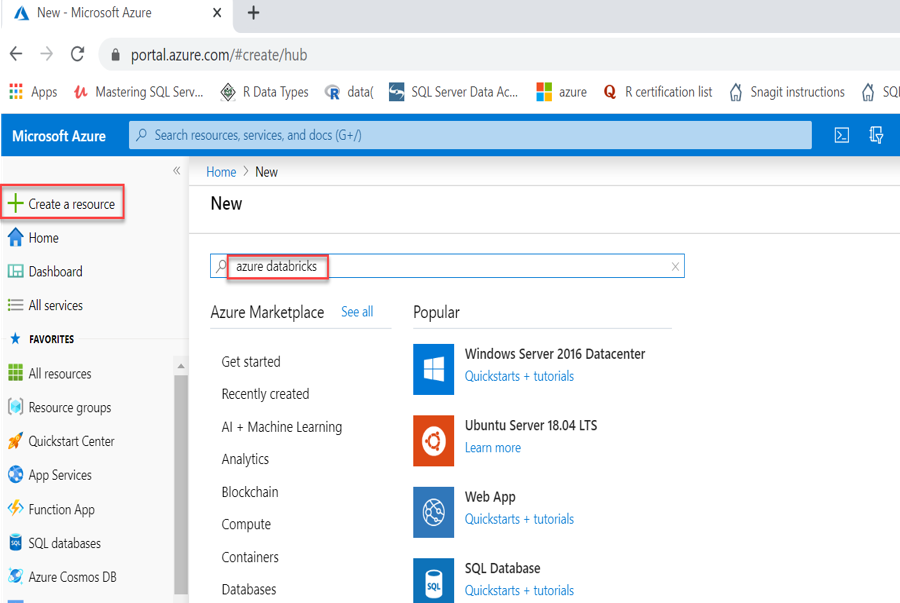
Đăng nhập vào Cổng Azure và nhấp vào Create a resource và gõ databricks trong hộp tìm kiếm:


Bấm vào Create như hình dưới đây:


Bạn sẽ được đưa đến màn hình hiển thị sau. Cung cấp những thông tin sau :
- Đăng ký– Chọn đăng ký của bạn
- Nhóm tài nguyên – Tôi đang sử dụng nhóm mà tôi đã tạo (azguidesurerg), bạn cũng có thể tạo mới cho nhóm này
- Tên vùng làm việc – Đây là tên (azdatabricks) mà bạn muốn đặt cho dịch vụ cơ sở dữ liệu của mình
- Vị trí – Chọn khu vực mà bạn muốn triển khai dịch vụ cơ sở dữ liệu của mình (Đông Hoa Kỳ)
- Bậc định giá – Tôi đang chọn DBU trả phí – 14 ngày miễn phí cho bản trình diễn này. Để tìm hiểu thêm thông tin chi tiết về các bậc Tiêu chuẩn và Cao cấp, hãy nhấp vào đây
Sau đó, nhấn vào Review + Create để xem lại các giá trị đã gửi và cuối cùng nhấp vào Create để tạo dịch vụ này:


Khi đã được tạo, hãy nhấp vào Go to resource trong tab thông báo để mở dịch vụ bạn vừa tạo:


Bạn hoàn toàn có thể xem 1 số ít chi tiết cụ thể đơn cử như URL, chi tiết cụ thể Ngân sách chi tiêu, v.v. về dịch vụ cơ sở tài liệu của bạn trên cổng thông tin .
Bấm vào Launch Workspace để mở cổng Azure Databricks


Bạn sẽ được nhu yếu đăng nhập lại để khởi chạy Databricks Workspace .
Ảnh chụp màn hình sau đây cho thấy trang chủ Databricks trên cổng Databricks. Trên Workspace, bạn có thể tạo sổ ghi chép và quản lý tài liệu của mình. Các Data bên dưới cho phép bạn tạo bảng và cơ sở dữ liệu. Bạn cũng có thể làm việc với nhiều nguồn dữ liệu khác nhau như Cassandra, Kafka, Azure Blob Storage, v.v. Nhấp vào Clusters trong danh sách dọc các tùy chọn:


Tạo một cụm Spark trong Azure Databricks Các cụm trong cơ sở dữ liệu trên Azure được xây dựng trong một môi trường spark Apache được quản lý hoàn toàn; bạn có thể tự động tăng hoặc giảm quy mô dựa trên nhu cầu kinh doanh. Bấm vào Create Cluster bên dưới trên Clusters:


Ảnh chụp màn hình hiển thị sau đây cho thấy một số ít tùy chọn thông số kỹ thuật để tạo một cụm cơ sở tài liệu mới. Chúng tôi đang tạo một cụm với 5,5 thời hạn chạy ( một công cụ giải quyết và xử lý tài liệu ), phiên bản Python 2 và dòng Standard_F4s được định thông số kỹ thuật ( tương thích với khối lượng việc làm thấp ). Vì đây là một bản diễn đạt nên chúng tôi không bật tính năng tự động hóa kiểm soát và điều chỉnh tỷ suất và cũng được cho phép tùy chọn kết thúc cụm này nếu nó không hoạt động giải trí trong 120 phút .
Cuối cùng, nhấp chuột vào Create Cluster trên New Cluster:


Về cơ bản, bạn hoàn toàn có thể định thông số kỹ thuật cụm của mình theo ý muốn. Các thông số kỹ thuật cụm khác nhau, gồm có cả Tùy chọn nâng cao, được diễn đạt rất chi tiết cụ thể ở ở đây trên trang tài liệu này của Microsoft .
Bạn hoàn toàn có thể thấy trạng thái của cụm là Đang chờ giải quyết và xử lý trong ảnh chụp màn hình hiển thị bên dưới. Điều này sẽ mất một khoảng chừng thời hạn để tạo một cụm .
Bài viết trên có có ích với bạn không ? Hãy cho chúng tôi biết quan điểm của bạn để nội dung bài viết hoàn toàn có thể cải tổ hơn. Đừng quên like, follow để không bỏ lỡ bất kể nội dung mới nhất của guidesure nhé !


Bây giờ cụm của chúng tôi đang hoạt động giải trí và đang chạy :


Theo mặc định, Databricks là một dịch vụ được quản trị trọn vẹn, có nghĩa là những tài nguyên link với cụm được tiến hành cho một nhóm tài nguyên bị khóa, databricks-rg-azdatabricks-3 … Như hình bên dưới. Đối với Dịch Vụ Thương Mại Databricks, azdatabricksVM, Disk và những dịch vụ tương quan đến mạng khác được tạo :


Bạn cũng hoàn toàn có thể nhận thấy rằng thông tin tài khoản Bộ nhớ chuyên sử dụng cũng được tiến hành trong nhóm Tài nguyên đã cho :


Tạo sổ ghi chép trong cụm Spark
Sổ ghi chép trong cụm tia lửa là giao diện dựa trên web cho phép bạn chạy mã và hình ảnh hóa bằng những ngôn từ khác nhau .
Khi cụm được thiết lập và chạy, bạn có thể tạo sổ ghi chép trong đó và cũng chạy các công việc Spark. Trong tab Không gian làm việc trên thanh menu dọc bên trái, hãy nhấp vào Create và chọn Notebook:


bên trong Create Notebookcung cấp tên Notebook, chọn ngôn ngữ (Python, Scala, SQL, R), tên cụm và nhấn Create. Thao tác này sẽ tạo một sổ ghi chép trong cụm Spark được tạo ở trên:


Vì tất cả chúng ta sẽ tò mò những góc nhìn khác nhau của Databricks Notebooks trong những bài viết sắp tới của tôi, tôi sẽ dừng bài đăng này tại đây .
Phần kết luận
Tôi đã nỗ lực lý giải những điều cơ bản về Azure Databricks theo cách dễ hiểu nhất tại đây. Chúng tôi cũng đã trình diễn cách bạn hoàn toàn có thể tạo Databricks bằng Azure Portal, tiếp theo là tạo một cụm và một sổ ghi chép trong đó. Mục đích của bài viết này là giúp người mới mở màn hiểu những nguyên tắc cơ bản về Databricks trong Azure. Hãy theo dõi những bài viết về Azure để tìm hiểu và khám phá thêm về công cụ can đảm và mạnh mẽ này .
Source: https://final-blade.com
Category: Kiến thức Internet