Tóm Tắt
Vậy Index là gì ??
Index là một cấu trúc tài liệu được dùng để xác định và truy vấn nhanh nhất vào tài liệu trong những bảng database
Index là một cách tối ưu hiệu suất truy vấn database bằng việc giảm lượng truy vấn vào bộ nhớ khi triển khai truy vấn
Index database dùng để làm gì?
Giả sử ta có một bảng User lưu thông tin của người dùng, ta muốn lấy ra thông tin của người dùng có trường tên (Name) là “HienNguyen”. Ta có truy vấn SQL sau: SELECT * FROM User WHERE Name = 'HienNguyen';
Bạn đang đọc: Những Điều Cần Biết Về Index Trong Database
Nếu không có Index cho cột Name, truy vấn sẽ phải chạy qua toàn bộ những Row của bảng User để so sánh và lấy ra những Row thỏa mãn nhu cầu. Vì vậy, khi số lượng bản ghi lớn, chuyện gì sẽ xảy ra ? ? Index được sinh ra để xử lý yếu tố này .
Index trỏ tới địa chỉ tài liệu trong một bảng, nó same same mục lục của quyển sách bạn đọc, nó giúp truy vấn trở nên nhanh gọn như việc bạn xem mục lục
- Index hoàn toàn có thể được tạo cho một hoặc nhiều cột trong database. Index thường được tạo mặc định cho primary key, foreign key. Ngoài ra, ta cũng hoàn toàn có thể tạo thêm index cho những cột nếu cần .
Cấu trúc của Index
Index gồm :
- Cột Search Key: chứa bản sao các giá trị của cột được tạo Index
- Cột Data Reference: chứa con trỏ trỏ đến địa chỉ của bản ghi có giá trị cột index tương ứng

Các kiểu index
1. B-Tree index
Thông thường khi nói đến index mà không chỉ rõ loại index thì default là sẽ sử dụng B-Tree index.
Cú pháp:
|
1 2 3 4 5 6 |
/ / Create index
CREATE INDEX id_index ON table_name
(column_name[,
column_name…])
USING BTREE; / / Or
ALTER TABLE table_name ADD INDEX id_index
(column_name[,
column_name…]) / / Drop index
DROP INDEX index_name ON table_name |
Các đặc điểm của B-Tree Index:
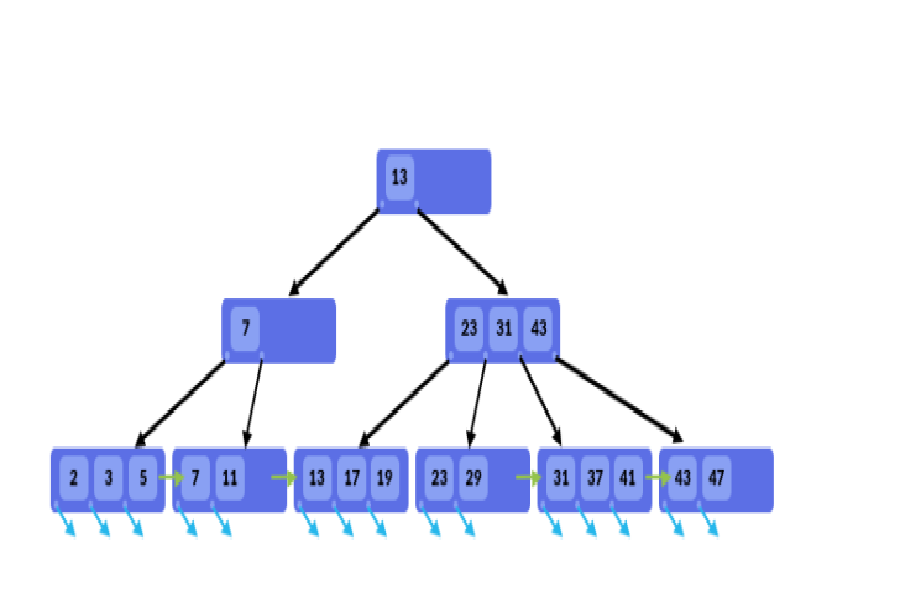
– Dữ liệu index được tổ chức và lưu trữ theo dạng tree, tức là có root, branch, leaf.
※Cách sắp xếp không phải theo dạng cây tìm kiếm nhị phân – Binary search tree vì số lá là mỗi node không bị giới hạn là 2.
– Giá trị của các node được tổ chức tăng dần từ trái qua phải.
– B-Tree index được sử dụng trong các biểu thức so sánh dạng: =, >, >=, <, <=, BETWEEN và LIKE. ⇒ Có thể tối ưu tốt cho câu lệnh ORDER BY
– Khi truy vấn dữ liệu thì CSDL sẽ không scan dữ liệu trên toàn bộ bảng để tìm dữ liệu, việc tìm kiếm trong B-Tree là 1 quá trình đệ quy, bắt đầu từ root node và tìm kiếm tới branch và leaf, đến khi tìm được tất cả dữ liệu – thỏa mãn với điều kiện truy vấn thì mới dùng lại.
2. Hash index
Hash index dựa trên giải thuật Hash Function (hàm băm). Tương ứng với mỗi khối dữ liệu (index) sẽ sinh ra một bucket key(giá trị băm) để phân biệt.
Cú pháp:
|
1 2 3 4 |
/ / Create index
CREATE INDEX id_index ON table_name
(column_name[,
column_name…])
USING HASH; / / Or
ALTER TABLE table_name ADD INDEX id_index
(column_name[,
column_name…])
USING HASH; |
Các đặc điểm của Hash Index:
– Khác với B-Tree, thì Hash index chỉ nên sử dụng trong các biểu thức toán tử là = và <>. Không sử dụng cho toán từ tìm kiếm 1 khoảng giá trị như > hay < .
– Không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order.
– Hash có tốc độ nhanh hơn kiểu B-Tree.
3. Các kiểu index tương ứng với Storage Engine
Việc chọn index theo kiểu B-Tree hay Hash ngoài yếu tố về mục tiêu sử dụng index thì nó còn phụ thuộc vào vào việc Storage Engine có tương hỗ loại index đó hay không .
| Storage Engine | Các kiểu index được hỗ trợ |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY/HEAP | HASH, BTREE |
| NDB | HASH, BTREE |
Dùng Index Database thế nào cho hiệu quả?
Mặc dù Index đóng vai trò quan trọng trong việc tối ưu truy vấn và tăng tốc độ tìm kiếm trong Database nhưng nhược điểm của nó là tốn thêm bộ nhớ để lưu trữ. Do vậy, việc Index cho các cột phải được tính toán cẩn thận
Dưới đây là một số ít Tips giúp bạn tạo Database index hiệu suất cao hơn :
- Nên Index những cột được dùng trong WHERE, JOIN và ORDER BY
- Dùng chức năng index prefix” or “multi-columns index” của MySQL. Vd: Nếu bạn tạo Index(first_name, last_name) thì k cần tạo Index(first_name)
- Dùng thuộc tính NOT NULL cho những cột được Index
- Không dùng Index cho các bảng thường xuyên có UPDATE, INSERT
- Không dùng Index cho các cột mà giá trị thường xuyên bị thay đổi
- Dùng câu lệnhEXPLAINgiúp ta biết được MySQL sẽ chạy truy vấn ra sao. Nó thể hiện thứ tự join, các bảng được join như thế nào. Giúp việc xem xét để viết truy vấn tối ưu, chọn cột để Index dễ dàng hơn
Source: https://final-blade.com
Category: Kiến thức Internet