Tóm Tắt
Tìm dữ liệu trong một tập nhiều dòng
Tập dữ liệu không có thứ tự
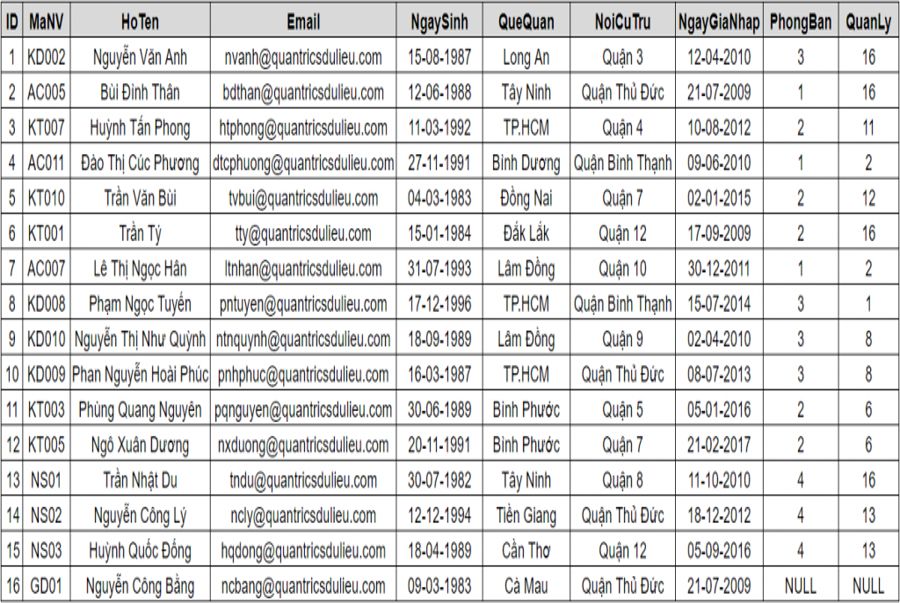
Dữ liệu trong cơ sở tài liệu quan hệ được tàng trữ dưới dạng bảng, hay hoàn toàn có thể nói cách khác là hàng và cột. Nhìn vào bảng tài liệu trong hình dưới đây và bạn hãy vấn đáp truy vấn “ tìm nhân viên cấp dưới có ID bằng 5 ”. Bạn sẽ làm thế nào ?

 Hình 1: Bảng dữ liệu NhanVien
Hình 1: Bảng dữ liệu NhanVien
Để đảm không bỏ sót có phải bạn sẽ duyệt từng dòng một từ trên xuống dưới, thanh tra rà soát xem cột ID của dòng nào có giá trị bằng 5 hay không ?
Nếu dòng này nằm ngay trên đầu hoặc ở dòng thứ 2 hoặc thứ 3 thì bạn sẽ nhanh chóng tìm thấy nó. Nhưng nếu nó nằm ở dưới cùng thì sao? Bạn phải duyệt qua hết bảng mới có kết quả cuối cùng.
Giả sử ngay dòng tiên phong cột ID đã bằng 5 rồi, liệu bạn có liên tục tìm xuống dưới không ? Bởi vì câu truy vấn của tất cả chúng ta không số lượng giới hạn chỉ tìm một người ( TOP 1 ) mà cũng không có ràng buộc nào nói mỗi ID là duy nhất. Do đó, bạn bắt buộc phải duyệt đến cuối bảng vì hoàn toàn có thể có một nhân viên cấp dưới khác có ID cũng bằng 5 thì sao .
Tập dữ liệu có thứ tự
Nếu bảng này được sắp xếp theo thứ tự tăng dần của cột ID thì thế nào ?

 Hình 2: Bảng dữ liệu NhanVien sắp xếp theo cột ID
Hình 2: Bảng dữ liệu NhanVien sắp xếp theo cột ID
Chúng ta hoàn toàn có thể lựa chọn duyệt bảng theo hướng từ trên xuống hoặc từ dưới lên. Ta hoàn toàn có thể Dự kiến giá trị cần tìm là 5 thì duyệt từ trên xuống gần hơn, nhưng nếu giá trị cần tìm là 15 thì duyệt từ dưới lên có lẽ rằng nhanh hơn ?
Đó là do ví dụ của tất cả chúng ta chỉ có vài dòng, nếu bảng NhanVien này có hàng trăm ngàn hoặc hàng triệu dòng thì thế nào ? Chưa kể giá trị ID không chắc là liên tục. Chúng ta sẽ không đoán được giá trị cần tìm ở đoạn nào nên chỉ hoàn toàn có thể chọn một trong hai hướng và duyệt đến đầu bên kia .
Trong trường hợp bảng đã sắp xếp theo thứ tự như này. Khi đã tìm thấy dòng có ID bằng 5 rồi, nếu có thêm nhân viên cấp dưới khác cùng ID thì hẳn phải ở ngay dòng sau đó .
Bạn chỉ cần nhìn thêm dòng tiếp nối có phải bằng 5 hay không. Nếu không phải thì kết thúc truy vấn, còn nếu là 5 thì kiểm tra thêm dòng tiếp nối cho đến khi không tìm thêm được giá trị tương tự như nữa .
Dữ liệu dù được sắp xếp theo thứ tự vẫn chưa giúp câu truy vấn chạy nhanh được. Nếu không may giá trị cần tìm nằm kề cuối thì ta vẫn phải duyệt hầu như là hết bảng. Đây vẫn chưa là index
Clustered index
Tìm kiếm với clustered index
Bây giờ, nếu ta tạo clustered index trên cột ID cho bảng này thì tài liệu được tổ chức triển khai như thế nào ? Chúng ta chạy câu lệnh đơn thuần sau để tạo index
CREATE UNIQUE CLUSTERED INDEX CIX_NhanVien ON NhanVien(ID ASC)
Những dòng tài liệu trong bảng được gom nhóm lại với nhau tạo thành page, một page có size 8KB và tùy thuộc vào size của mỗi dòng mà chứa được số lượng tương ứng. Giả dụ bảng NhanVien trên có size 2000 bytes cho mỗi dòng, nên mỗi page sẽ chứa được 4 dòng như hình bên dưới

 Hình 3: index B-Tree
Hình 3: index B-Tree
Cột ID làm clustered index key nên tài liệu của bảng sẽ được sắp xếp theo giá trị tăng dần trên cột này .
Chúng ta thấy những dòng tài liệu với ID từ 1 đến 4 nằm trong page thứ nhất. Từ 5 đến 8 nằm trong page thứ hai. Từ 9 đến 12 thuộc page thứ 3 và ID từ 13 đến 16 thuộc page thứ 4 .
Các page này thể hiện đầy đủ dữ liệu của bảng và liên kết hai chiều với nhau theo từng cặp nằm cạnh nhau hoặc có thể bất kì khoảng cách nào. Chỉ cần có liên kết là thể hiện được thứ tự của dữ liệu.
Phía bên trái có một page khác chứa các giá trị 13, 9, 5 và NULL. Đây có thể xem là page mô tả rút gọn dữ liệu của cột ID.
Mỗi một dòng trong page này đại diện thay mặt một tập tài liệu ở page mà nó link tới. Và page được link tới này hoàn toàn có thể lại chứa những dòng link tới những page khác ( nhiều cấp ). Tất nhiên tài liệu trong page bên trái là clustered key, trong hình 3 chính là những giá trị từ cột ID .
Cấu trúc tài liệu này gọi là B-Tree, nó sẽ giúp SQL Server xác lập vị trí dòng tài liệu cực nhanh vì khoảng trống tìm kiếm sẽ giảm đi đáng kể trải qua cấu trúc này. Hãy thử tìm lại nhân viên cấp dưới có ID bằng 5 xem .
Thay vì duyệt từ đầu bảng như lúc nãy, giờ ta chỉ cần duyệt những dòng trong page bên trái. Xuất phát từ bất kể hướng nào cho đến khi gặp giá trị 5. Lần theo đường dẫn link tới page ở bên phải rồi duyệt page này sẽ tìm thấy giá trị 5 .
Vì tất cả chúng ta khai báo clustered index key là unique nên việc tìm kiếm sẽ kết thúc ngay khi tìm thấy dòng tài liệu có giá trị ID bằng 5. Nếu không unique SQL Server sẽ tìm thêm ở page bên cạnh .
Có thể bạn sẽ nói làm như vậy cũng triển khai nhiều phép so sánh, gần bằng duyệt từng dòng trực tiếp trên bảng. Nhưng đây là bảng có kích cỡ nhỏ, bạn hãy tưởng tượng nếu bảng có một triệu pages thì thế nào ? Thời gian tìm kiếm một dòng tài liệu khi đó không còn nhờ vào vào số lượng dòng mà là chiều cao của cây index .
Đây chính là cách hoạt động giải trí của index, nó sẽ giúp tất cả chúng ta khuynh hướng tìm kiếm trong một tập tài liệu nhỏ hơn và do đó sẽ có vận tốc nhanh hơn .
Cấu tạo của clustered index
Những page chứa tài liệu của bảng như thế này gọi là leaf node, xét theo Lever gọi là leaf level hay còn gọi level 0. Cao hơn sẽ có level 1 và cứ tăng lên 1 như vậy cho đến khi chứa đủ tài liệu thì dừng .
Cấp cao nhất sẽ là root level. Những level ở giữa root và leaf thì gọi là intermediate level. Trong hình 3 không có intermediate level, bạn có thể xem minh họa ở trang này.
Nếu leaf level ( của clustered index ) chứa tài liệu của bảng thì những level trên chứa cái gì ? Những tài liệu này từ đâu mà có ?
Mỗi page ở level trên cũng có kích cỡ 8KB. Dữ liệu được chứa trong này là clustered key của bảng, được gọi là index record. Kích thước của index record sẽ quyết định hành động số lượng record có trong page .
Giả sử cột ID có kiểu tài liệu INT ( 4 bytes ) cộng với những ngân sách tổ chức triển khai tàng trữ nữa thành 11 bytes cho mỗi record. Với khoảng trống 8096 bytes mỗi page hoàn toàn có thể chứa tối đa 736 index records ( đo lường và thống kê tương đối ). Tương ứng với 736 pages ở level dưới .
Bây giờ ta thấy rõ rằng duyệt 736 pages để tìm một giá trị sẽ tốn thời gian hơn nhiều so với duyệt 2 pages. Một page ở level 1 (root page) và 1 page ở level 0 (leaf page). Đây chính là cách mà index giúp ta tăng tốc độ tìm kiếm.
Chúng ta hãy cùng khảo sát clustered index trên bảng NhanVien để kiểm chứng những điều trên. Sử dụng hai câu lệnh DBCC IND ( ) và DBCC PAGE ( ) như hướng dẫn ở bài trước mình từng đề cập. ( Mình sẽ update scripts tạo bảng NhanVien và insert dữ liệu sau )

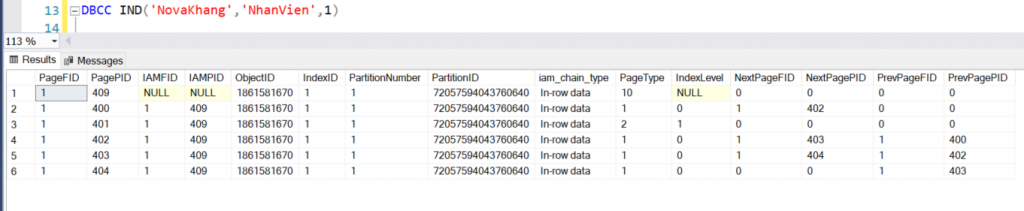 Hình 4: Danh sách data/index pages của clustered index bảng NhanVien
Hình 4: Danh sách data/index pages của clustered index bảng NhanVien
Các tham số từ trái qua phải gồm tên database, tên bảng và index_id. Chúng ta hãy chú ý quan tâm đến bảng hiệu quả. PagePID là ID của những page thuộc bảng NhanVien trên FileID 1 ( vì nhiều bảng hoàn toàn có thể được lưu trên cùng file và một bảng cũng hoàn toàn có thể được lưu trên nhiều file ) .
PageType 10 thuộc system dùng để quản trị space của bảng ta trong thời điểm tạm thời chưa chăm sóc. PageType 1 chính là data page chứa tài liệu bảng NhanVien. PageType 2 là index page chứa index record, và cũng là root page trong ví dụ của tất cả chúng ta .
Cột IndexLevel bộc lộ đúng như những gì tất cả chúng ta nói ở trên. Level 0 thấp nhất cũng là leaf level, nơi chứa tài liệu của bảng ( data page ). Level 1 cao nhất nên là root level. Hãy quan tâm PagePID của root page vì tất cả chúng ta sẽ khảo sát nội dung của nó .
Bốn page có level bằng 0 được link với hai page bên cạnh biểu lộ qua cột PrevPagePID và NextPagePID. Cùng với thông tin FileID trải qua cột NextPageFID và PrevPageFID .
Tiếp theo, hãy cùng xem nội dung page root level có giống những gì tất cả chúng ta đã miêu tả không nhé .

 Hình 5: Nội dung page root của clustered index
Hình 5: Nội dung page root của clustered index
Page root có ID 401 và nội dung của nó có 4 dòng chứa key ID lần lượt NULL, 5, 9, 13. Mỗi dòng này link tới page ở level 0 có pageID ở chột ChildPageId. Giống như những gì tất cả chúng ta thấy trong hình 3 .
Vậy khi tìm kiếm một giá trị, SQL Server sẽ mở màn từ root page, lần theo giá trị trong page đó đi xuống những level thấp hơn và ở đầu cuối sẽ đến được page chứa giá trị cần tìm. Thời gian của việc tìm kiếm này phụ thuộc vào vào chiều cao của index ( số lượng level ). Và số lượng level nhờ vào vào kích cỡ index key .
Tóm lại clustered index trong SQL Server có những đặc thù sau
- Dữ liệu của bảng sẽ được sắp xếp theo thứ tự clustered key
- Sử dụng cấu trúc B-Tree để tạo ra các cấp độ lưu trữ key hỗ trợ tìm kiếm
- Index có level càng cao thì việc tìm kiếm càng tốn thời gian hơn
- Level của index phụ thuộc vào độ lớn dữ liệu trong bảng và kích thước của index key
Share this:
Like this:
Like
Xem thêm: Lập trình tân binh | 2.6. Lớp và con trỏ
Loading …
Related
Source: https://final-blade.com
Category : Kiến thức Internet