Tóm Tắt
Tại sao lại là RDD?
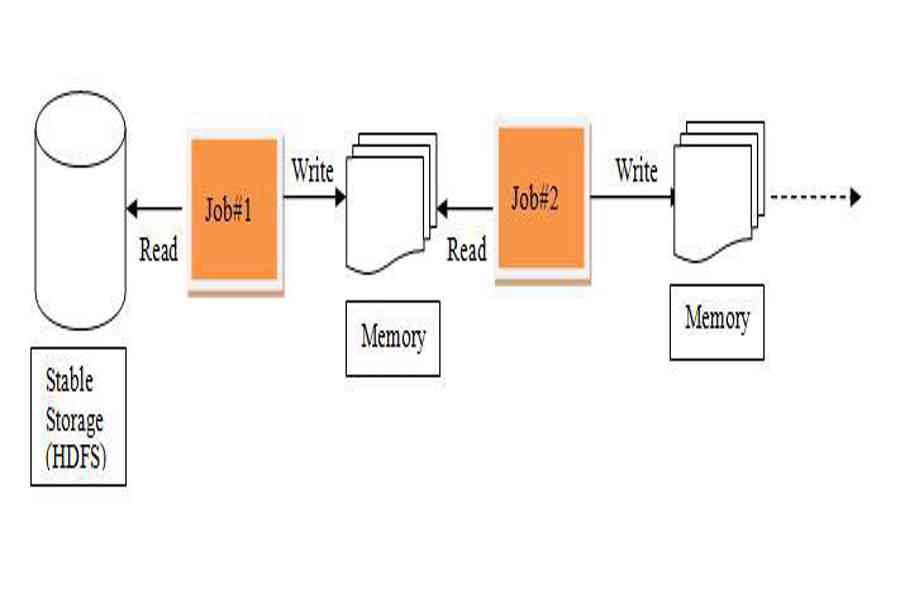
Nói chung, Apache Spark đã vượt qua Hadoop ( MapReduce ), vì nhiều quyền lợi và nghĩa vụ mà nó mang lại về mặt thực thi nhanh hơn trong những thuật toán xử lý và giải quyết và xử lý lặp như Học máy. Trong bài đăng này, chúng tôi sẽ nỗ lực nỗ lực hiểu điều gì làm cho tia RDD trở nên hữu dụng trong nghiên cứu và điều tra và nghiên cứu và phân tích hàng loạt .Khi nói đến điện toán phân tán lặp, tức là xử lý và xử lý tài liệu qua nhiều việc làm trong những thống kê giám sát như Hồi quy logistic, phân cụm K-nghĩa, thuật toán xếp hạng Trang, khá thông dụng để sử dụng lại hoặc san sẻ tài liệu giữa nhiều việc làm hoặc bạn trọn vẹn hoàn toàn có thể muốn thực thi nhiều việc làm truy vấn đặc biệt quan trọng quan trọng trên một tập tài liệu được san sẻ .
Có một yếu tố tiềm ẩn với việc tái sử dụng tài liệu hoặc san sẻ tài liệu trong những mạng lưới hệ thống máy tính phân tán hiện có ( như MapReduce ) và đó là, bạn cần tàng trữ tài liệu trong 1 số ít shop phân tán không thay đổi trung gian như HDFS hoặc Amazon S3. Điều này làm cho việc giám sát tổng thể và toàn diện những việc làm chậm hơn vì nó tương quan đến nhiều hoạt động giải trí IO, sao chép và tuần tự hóa trong tiến trình .
Bạn đang đọc: RDD trong Spark là gì và tại sao chúng ta cần nó?
Bạn đang đọc : RDD trong Spark là gì và tại sao tất cả chúng ta cần nó ?

Xử lý lặp trong MapReduceRDD, nỗ lực nỗ lực giải quyết và xử lý những yếu tố này bằng cách được cho phép thống kê giám sát trong bộ nhớ phân tán chịu lỗi .

Xử lý lặp trong Spark
Bây giờ, hãy hiểu đúng chuẩn RDD là gì và cách nó đạt được năng lực chịu lỗi –
Xem thêm : Vai trò của mái ấm gia đình trong xã hội lúc bấy giờ
RDD – Bộ dữ liệu phân tán linh hoạt
RDD là bộ sưu tập những bản ghi không khi nào đổi khác và được phân vùng, chỉ trọn vẹn hoàn toàn có thể được tạo bởi những hoạt động giải trí vui chơi đơn cử thô như map, bộ lọc, nhóm, v.v. Bằng những thao tác chi tiết cụ thể đơn cử thô, điều đó có nghĩa là những hoạt động giải trí vui chơi được vận dụng trên tổng thể và toàn diện những thành phần trong bộ tài liệu. RDD chỉ trọn vẹn hoàn toàn có thể được tạo bằng cách đọc tài liệu từ bộ tàng trữ không biến hóa như HDFS hoặc bằng cách quy đổi trên RDD hiện có .
Bây giờ, làm thế nào là giúp đỡ cho dung sai lỗi?
Vì RDD được tạo qua một tập hợp những phép đổi khác, nó ghi nhật ký những phép đổi khác đó, chứ không phải là tài liệu thực tiễn. Sơ đồ đổi khác để tạo ra một RDD được gọi là Đồ thị Lineage .Ví dụ –
firstRDD=spark.textFile("hdfs://...")
secondRDD=firstRDD.filter(someFunction);
thirdRDD = secondRDD.map(someFunction);Biểu đồ truyền thừa Spark RDD

Trong trường hợp chúng tôi mất 1 số ít phân vùng của RDD, chúng tôi trọn vẹn hoàn toàn có thể phát lại quy đổi trên phân vùng đó theo dòng để đạt được cùng một thống kê giám sát và thống kê, thay vì sao chép tài liệu trên nhiều nút. Đặc điểm này là quyền lợi và nghĩa vụ lớn nhất của RDD, vì nó tiết kiệm chi phí ngân sách và ngân sách rất nhiều nỗ lực trong quản trị và nhân rộng tài liệu và do đó đạt được những đo lường và thống kê và thống kê nhanh hơn .
Source: https://final-blade.com
Category : Tiền Điện Tử – Tiền Ảo