Cộng đồng đam mê dữ liệu lớn và khoa học dữ liệu chắc hẳn không còn xa lạ với “con voi đồ chơi” Hadoop. Đây là hệ sinh thái được thiết kế bởi Doug Cutting và Michael Cafarella vào năm 2005, lấy cảm hứng từ Google. Hadoop lưu trữ lượng dữ liệu khổng lồ thông qua một hệ thống được gọi là Hệ thống tệp phân tán Hadoop (HDFS) và xử lý dữ liệu này bằng công nghệ Map Reduce. Các thiết kế của HDFS và Map Reduce được phát triển với nguồn cảm hứng từ Hệ thống tệp của Google (GFS) và Map Reduce. Trong bài viết này, chúng ta sẽ cùng nhau tìm hiểu tổng quan về hệ sinh thái Hadoop, từ những ưu điểm vượt trội, các thành phần của hệ sinh thái đến các phiên bản hiện có của Hadoop.
Tóm Tắt
Hệ sinh thái Hadoop và ưu điểm vượt trội so với phương pháp truyền thống
Cách tiếp cận truyền thống lưu trữ và xử lý các tập dữ liệu trên máy tính cục bộ. Khi quy mô dữ liệu bắt đầu tăng lên, các máy tính này không còn đủ khả năng đáp ứng nhu cầu lưu trữ. Vì vậy, sau đó, dữ liệu bắt đầu được lưu trữ từ xa trên các máy chủ. Khi cần xử lý, dữ liệu sẽ trải qua quá trình tìm nạp từ máy chủ. Quy trình này thường rất phức tạp và tốn tài nguyên. Đây được gọi là tiếp cận kiểu doanh nghiệp (enterprise approach)
Với cách tiếp cận mới của Hadoop, dữ liệu thay vì được tìm nạp trên các máy cục bộ thì sẽ nhận được truy vấn. Việc truy vấn để xử lý dữ liệu yêu cầu ít tài nguyên hơn. Hơn nữa, tại máy chủ, truy vấn được chia thành nhiều phần. Tất cả các phần này xử lý dữ liệu song song và đồng thời nhờ Map Reduce. Do đó, giờ đây, không chỉ không cần tìm nạp dữ liệu mà việc xử lý cũng mất ít thời gian hơn. Kết quả của truy vấn sau đó được gửi đến người dùng. Như vậy, Hadoop làm cho cách thức lưu trữ, xử lý và phân tích dữ liệu trở nên dễ dàng hơn so với các cách tiếp cận truyền thống.
Ngoài ra, Hadoop cũng sở hữu một số ưu điểm khác như:
- Khả thi về mặt kinh tế: Hadoop lưu trữ và xử lý dữ liệu rẻ hơn so với cách tiếp cận truyền thống vì các máy được sử dụng thực tế chỉ là phần cứng có sẵn.
- Dễ sử dụng: Các dự án hoặc bộ công cụ do Apache Hadoop cung cấp rất dễ sử dụng để phân tích các tập dữ liệu phức tạp.
- Mã nguồn mở: Vì Hadoop được phân phối dưới dạng một phần mềm mã nguồn mở theo Giấy phép Apache, vì vậy người dùng không cần phải trả phí mà chỉ cần tải xuống và sử dụng.
- Khả năng chịu lỗi: Vì Hadoop lưu trữ ba bản sao dữ liệu, nên ngay cả khi một bản sao bị mất do bất kỳ lỗi phần cứng nào, dữ liệu vẫn được giữ an toàn.
- Khả năng mở rộng: Hadoop có khả năng mở rộng cao. Nếu cần mở rộng quy mô hoặc thu nhỏ cụm, người dùng chỉ cần thay đổi số lượng phần cứng có sẵn trong cụm.
- Xử lý phân tán: HDFS và Map Reduce đảm bảo lưu trữ và xử lý dữ liệu được phân tán.
- Vị trí của dữ liệu: Đây là một trong những đặc điểm hấp dẫn nhất của Hadoop. Trong Hadoop, để xử lý một truy vấn trên một tập dữ liệu, thay vì đưa dữ liệu đến máy tính cục bộ, người dùng gửi truy vấn đến máy chủ và tìm nạp kết quả cuối cùng từ đó. Đây được gọi là cục bộ hóa dữ liệu.
Các thành phần chính của Hadoop và giải pháp cho các bài toán trong dữ liệu lớn
Hệ sinh thái Hadoop được miêu tả bằng sơ đồ dưới đây
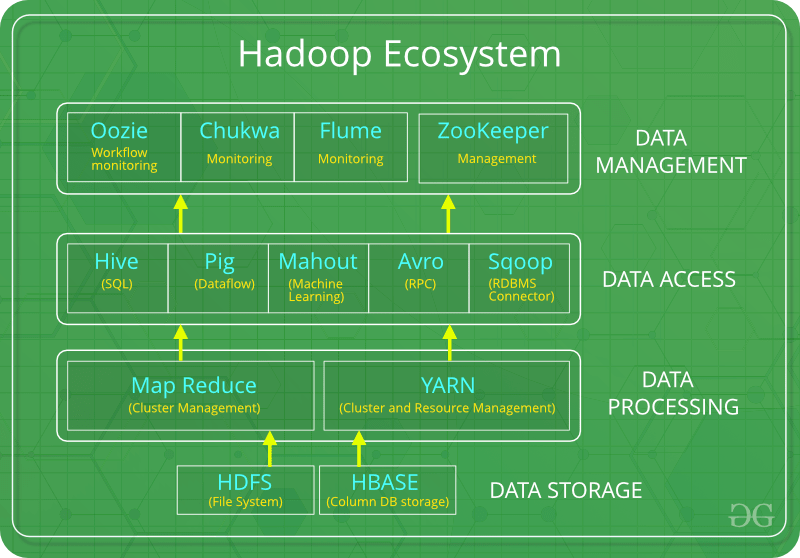
Các thành phần chính của Hadoop bao gồm:
- HDFS: Hệ thống tệp phân tán Hadoop là một hệ thống tệp chuyên dụng để lưu trữ dữ liệu lớn với một nhóm phần cứng có sẵn hoặc phần cứng có mô hình truy cập trực tuyến. HDFS cho phép dữ liệu được lưu trữ tại nhiều điểm nút trong cụm, đảm bảo an ninh dữ liệu và khả năng chịu lỗi.
Cách HDFS giải bài toán trong dữ liệu lớn: Trong PC cục bộ, theo mặc định, kích thước khối trong Đĩa cứng là 4KB. Khi cài đặt Hadoop, HDFS theo mặc định sẽ thay đổi kích thước khối thành 64 MB, thậm chí có thể lên đến 128 MB. Lúc này, HDFS phối hợp với Data Node (lưu trữ siêu dữ liệu – metadata) và Name Node (lưu trữ dữ liệu thực). Với kích thước khối là 64 MB, dung lượng cần thiết để lưu trữ siêu dữ liệu được giảm xuống, do đó làm cho HDFS hoạt động tốt hơn. Ngoài ra, Hadoop lưu trữ ba bản sao của mọi tập dữ liệu tại ba địa điểm khác nhau. Điều này giúp đảm bảo khả năng chịu lỗi của Hadoop.
- Map Reduce: Dữ liệu sau khi lưu trữ trong HDFS cũng cần được xử lý. Lúc này, giả sử gửi đi một truy vấn xử lý tập dữ liệu trong HDFS, Hadoop sẽ xác định nơi lưu trữ dữ liệu (Mapping), sau đó, chia truy vấn thành nhiều phần và kết quả của tất cả những phần này được kết hợp lại để gửi cho người dùng. Đây được gọi là quá trình giảm thiểu. Với Map Reduce, việc chia truy vấn thành nhiều phần và tiến hành xử lý song song, đồng thời giúp đẩy nhanh tốc độ cũng như tối ưu hiệu quả xử lý.
- YARN: YARN là viết tắt của Yet Another Resource Negotiator. Nó là một hệ điều hành dành riêng cho Hadoop, giúp quản lý các tài nguyên của cụm và cũng có chức năng như một framework để lập lịch công việc.
Các phiên bản hiện có của Hadoop
Hiện Hadoop có 3 phiên bản như dưới đây:
- Hadoop 1: Đây là phiên bản đầu tiên và cơ bản nhất của Hadoop. Nó bao gồm Hadoop Common, Hadoop Distributed File System (HDFS) và Map Reduce.

- Hadoop 2: Sự khác biệt duy nhất giữa Hadoop 1 và Hadoop 2 là Hadoop 2 cũng chứa YARN (Yet Another Resource Negotiator). YARN giúp quản lý tài nguyên và lập lịch trình tác vụ thông qua hai trình nền là theo dõi công việc và theo dõi tiến độ.

- Hadoop 3: Đây là phiên bản gần đây của Hadoop. Hadoop 3 có đóng góp quan trọng, giúp giải quyết lỗi một điểm bằng cách có nhiều Name Nodes. Đồng thời, phiên bản này cũng có nhiều lợi thế khác như xóa mã hóa, sử dụng phần cứng GPU và Dockers vượt trội hơn so với các phiên bản trước của Hadoop.