Đăng ký nhận thông tin về những video mới nhất
Mục lục bài viết :
- Giới thiệu Pandas DataFrame
- Tạo dữ liệu gấu trúc
- Tạo dữ liệu gấu trúc bằng từ điển
- Tạo dữ liệu gấu trúc với danh sách
- Tạo dữ liệu gấu trúc với Mảng NumPy
- Tạo dữ liệu gấu trúc từ tệp
- Truy xuất nhãn và dữ liệu
- Pandas DataFrame Labels as Sequences
- Dữ liệu dưới dạng Mảng NumPy
- Loại dữ liệu
- Dữ liệu gấu trúc
- Truy cập và sửa đổi dữ liệu
- Nhận dữ liệu với người truy cập
- Thiết lập dữ liệu với trình truy cập
- Chèn và Xóa dữ liệu
- Chèn và xóa hàng
- Chèn và Xóa các Cột
- Áp dụng các phép toán số học
- Áp dụng các hàm NumPy và SciPy
- Sắp xếp dữ liệu gấu trúc
- Lọc dữ liệu
- Xác định thống kê dữ liệu
- Xử lý dữ liệu bị thiếu
- Tính toán với dữ liệu bị thiếu
- Làm đầy dữ liệu bị thiếu
- Xóa hàng và cột có dữ liệu bị thiếu
- Lặp lại trên một dữ liệu gấu trúc
- Làm việc với chuỗi thời gian
- Tạo DataFrames với nhãn chuỗi thời gian
- Lập chỉ mục và cắt lát
- Lấy mẫu lại và cán
- Lập kế hoạch với dữ liệu gấu trúc
- Đọc thêm
- Phần kết luận
Các Pandas DataFrame là một cấu trúc có chứa dữ liệu hai chiều và tương ứng của nó nhãn . DataFrames được sử dụng rộng rãi trong khoa học dữ liệu , máy học , máy tính khoa học và nhiều lĩnh vực sử dụng nhiều dữ liệu khác.
DataFrames tựa như như bảng SQL hoặc bảng tính mà bạn thao tác trong Excel hoặc Calc. Trong nhiều trường hợp, DataFrame nhanh hơn, dễ sử dụng hơn và mạnh hơn bảng hoặc bảng tính vì chúng là một phần không hề thiếu của hệ sinh thái Python và NumPy .
Trong hướng dẫn này, bạn sẽ học :
- Pandas DataFrame là gì và cách tạo một Pandas DataFrame
- Cách truy cập, sửa đổi, thêm, sắp xếp, lọc và xóa dữ liệu
- Cách xử lý các giá trị bị thiếu
- Cách làm việc với dữ liệu chuỗi thời gian
- Cách nhanh chóng trực quan hóa dữ liệu
Đã đến lúc khởi đầu với Pandas DataFrames !
Tóm Tắt
Giới thiệu Pandas DataFrame
Pandas DataFrames là cấu trúc tài liệu chứa :
- Dữ liệu được tổ chức theo hai thứ nguyên , hàng và cột
- Các nhãn tương ứng với các hàng và cột
Bạn hoàn toàn có thể khởi đầu thao tác với DataFrames bằng cách nhập Pandas :
>> >
>> >import pandas as pd
Bây giờ bạn đã nhập Pandas, bạn hoàn toàn có thể thao tác với DataFrames .
Hãy tưởng tượng bạn đang sử dụng Pandas để phân tích dữ liệu về các ứng viên cho vị trí phát triển ứng dụng web bằng Python . Giả sử bạn quan tâm đến tên, thành phố, tuổi và điểm của ứng viên trong bài kiểm tra lập trình Python hoặc py-score:
name |
city |
age |
py-score |
|
|---|---|---|---|---|
101 |
Xavier |
Mexico City |
41 |
88.0 |
102 |
Ann |
Toronto |
28 |
79.0 |
103 |
Jana |
Prague |
33 |
81.0 |
104 |
Yi |
Shanghai |
34 |
80.0 |
105 |
Robin |
Manchester |
38 |
68.0 |
106 |
Amal |
Cairo |
31 |
61.0 |
107 |
Nori |
Osaka |
37 |
84.0 |
Trong bảng này, dòng đầu tiên chứa các nhãn cột ( name, city, age, và py-score). Cột đầu tiên chứa các nhãn hàng ( 101,, 102v.v.). Tất cả các ô khác được lấp đầy bởi các giá trị dữ liệu .
Bây giờ bạn có mọi thứ bạn cần để tạo Pandas DataFrame .
Có một số cách để tạo Pandas DataFrame. Trong hầu hết các trường hợp, bạn sẽ sử dụng hàm DataFrametạo và cung cấp dữ liệu, nhãn và thông tin khác. Bạn có thể chuyển dữ liệu dưới dạng danh sách hai chiều , bộ tuple hoặc mảng NumPy . Bạn cũng có thể chuyển nó dưới dạng từ điển hoặc phiên bản PandasSeries hoặc là một trong một số kiểu dữ liệu khác không được đề cập trong hướng dẫn này.
Đối với ví dụ này, giả sử bạn đang sử dụng từ điển để chuyển tài liệu :
>> >
>> >data = {
... ' name ': [' Xavier ', ' Ann ', ' Jana ', ' Yi ', ' Robin ', ' Amal ', ' Nori '] ,
... ' city ': [' Mexico City ', ' Toronto ', ' Prague ', ' Shanghai ',
... ' Manchester ', ' Cairo ', ' Osaka '] ,
... ' age ': [41, 28, 33, 34, 38, 31, 37] ,
... ' py-score ': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
...}
>> >row_labels = [101, 102, 103, 104, 105, 106, 107]
datalà một biến Python đề cập đến từ điển chứa dữ liệu ứng viên của bạn. Nó cũng chứa các nhãn của các cột:
'name''city''age''py-score'
Cuối cùng, row_labelsđề cập đến một danh sách có chứa nhãn của các hàng, là các số từ 101đến 107.
Bây giờ bạn đã chuẩn bị sẵn sàng để tạo Pandas DataFrame :
>> >
>> >df = pd.DataFrame(data=data, index=row_labels)
>> >df
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
Đó là nó! dflà một biến chứa tham chiếu đến Pandas DataFrame của bạn. Pandas DataFrame này trông giống như bảng ứng cử viên ở trên và có các tính năng sau:
- Các nhãn hàng từ
101đến107 - Cột nhãn như
'name','city','age', và'py-score' - Dữ liệu như tên ứng viên, thành phố, độ tuổi và điểm kiểm tra Python
Hình này cho thấy các nhãn và dữ liệu từ df:
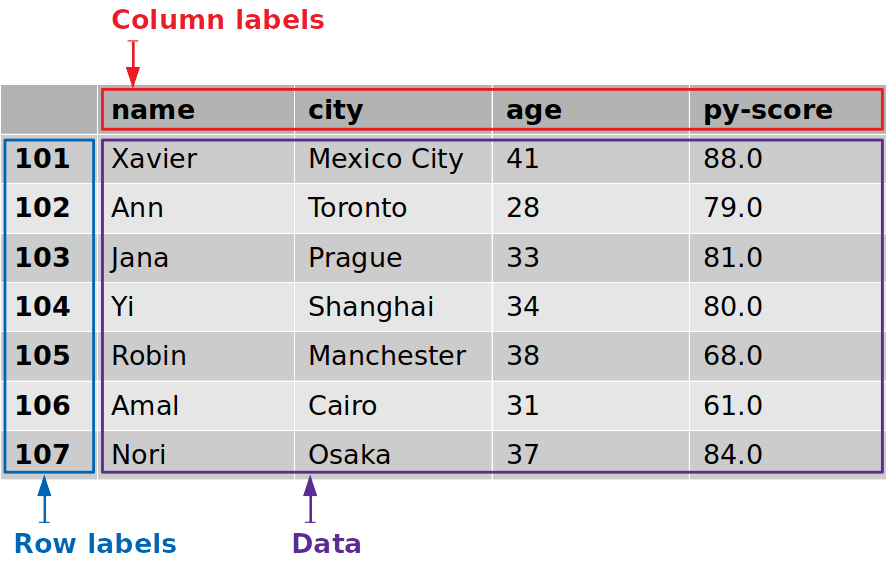
Các nhãn hàng được viền màu xanh lam, trong khi những nhãn cột được viền màu đỏ và những giá trị tài liệu được viền màu tím .
Pandas DataFrames đôi khi có thể rất lớn, khiến việc xem xét tất cả các hàng cùng một lúc là không thực tế. Bạn có thể sử dụng .head()để hiển thị một số mục đầu tiên và .tail()để hiển thị một số mục cuối cùng:
>> >
>> >df.head(n=2)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
>> >df.tail(n=2)
name city age py-score
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
Đó là cách bạn có thể hiển thị chỉ phần đầu hoặc phần cuối của Pandas DataFrame. Tham số nchỉ định số hàng sẽ hiển thị.
Lưu ý : Có thể có ích khi coi Pandas DataFrame như một từ điển gồm những cột, hoặc Chuỗi Pandas, với nhiều tính năng bổ trợ .
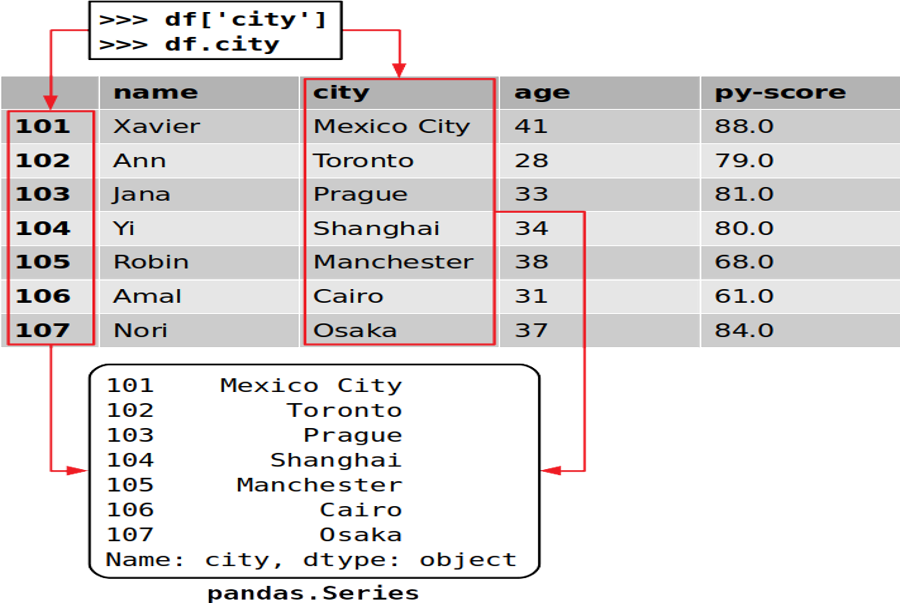
Bạn hoàn toàn có thể truy vấn một cột trong Pandas DataFrame giống như cách bạn lấy giá trị từ từ điển :
>> >
>> >cities = df[' city ']
>> >cities
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name : city, dtype : object
Đây là cách thuận tiện nhất để lấy một cột từ Pandas DataFrame .
Nếu tên của cột là một chuỗi là mã định danh Python hợp lệ, thì bạn hoàn toàn có thể sử dụng ký hiệu dấu chấm để truy vấn nó. Nghĩa là, bạn hoàn toàn có thể truy vấn cột giống như cách bạn lấy thuộc tính của một thành viên lớp :
>> >
>> >df.city
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name : city, dtype : object
Đó là cách bạn có được một cột cụ thể. Bạn đã trích xuất cột tương ứng với nhãn 'city', trong đó có vị trí của tất cả các ứng viên công việc của bạn.
Điều quan trọng cần chú ý quan tâm là bạn đã trích xuất cả tài liệu và nhãn hàng tương ứng :
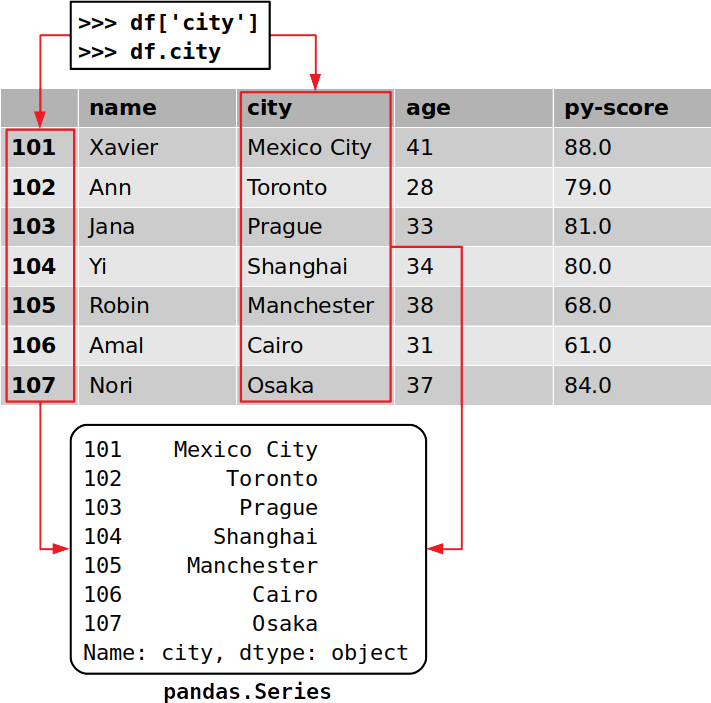
Mỗi cột của Pandas DataFrame là một ví dụ của pandas.Seriescấu trúc chứa dữ liệu một chiều và nhãn của chúng. Bạn có thể lấy một mục của một Seriesđối tượng giống như cách bạn làm với từ điển, bằng cách sử dụng nhãn của nó làm khóa:
>> >
>> >cities[102]
' Toronto '
Trong trường hợp này, 'Toronto'là giá trị dữ liệu và 102là nhãn tương ứng. Như bạn sẽ thấy trong phần sau , có nhiều cách khác để lấy một mục cụ thể trong Pandas DataFrame.
Bạn cũng có thể truy cập vào toàn bộ một hàng với các accessor .loc[] :
>> >
>> >df.loc[103]
name Jana
city Prague
age 33
py-score 81
Name : 103, dtype : object
Lần này, bạn đã trích xuất hàng tương ứng với nhãn 103chứa dữ liệu cho ứng viên được đặt tên Jana. Ngoài các giá trị dữ liệu từ hàng này, bạn đã trích xuất nhãn của các cột tương ứng:
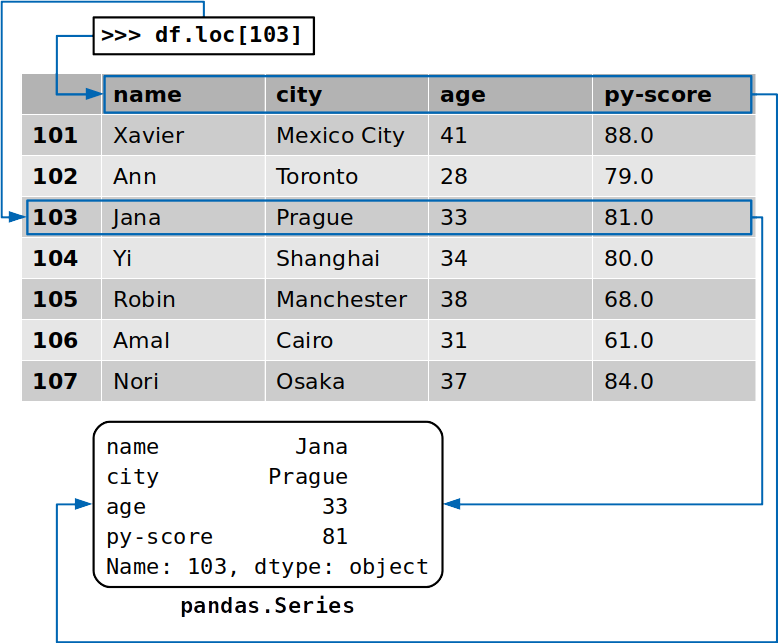
Hàng được trả về cũng là một ví dụ của pandas.Series.
Tạo dữ liệu gấu trúc
Như đã đề cập, có một số cách để tạo Pandas DataFrame. Trong phần này, bạn sẽ học cách làm điều này bằng cách sử dụng hàm DataFrametạo cùng với:
- Từ điển Python
- Danh sách Python
- Mảng NumPy hai chiều
- Các tập tin
Ngoài ra còn có những giải pháp khác mà bạn hoàn toàn có thể tìm hiểu và khám phá trong tài liệu chính thức .
Bạn hoàn toàn có thể khởi đầu bằng cách nhập Pandas cùng với NumPy, mà bạn sẽ sử dụng trong những ví dụ sau :
>> >
>> >import numpy as np
>> >import pandas as pd
Đó là nó. Bây giờ bạn đã chuẩn bị sẵn sàng để tạo một số ít DataFrames .
Tạo dữ liệu gấu trúc bằng từ điển
Như bạn đã thấy, bạn hoàn toàn có thể tạo Pandas DataFrame bằng từ điển Python :
>> >
>> >d = {' x ': [1, 2, 3], ' y ': np.array( [2, 4, 8] ), ' z ': 100}
>> >pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
Các khóa của từ điển là nhãn cột của DataFrame và giá trị từ điển là giá trị dữ liệu trong các cột DataFrame tương ứng. Các giá trị có thể được chứa trong một tuple , danh sách , mảng NumPy một chiều , đối tượng PandasSeries hoặc một trong số các kiểu dữ liệu khác. Bạn cũng có thể cung cấp một giá trị duy nhất sẽ được sao chép dọc theo toàn bộ cột.
Có thể kiểm soát thứ tự của các cột bằng columnstham số và nhãn hàng bằng index:
>> >
>> >pd.DataFrame(d, index=[100, 200, 300], columns=[' z ', ' y ', ' x '] )
z y x
100 100 2 1
200 100 4 2
300 100 8 3
Như bạn thấy, bạn đã chỉ định các nhãn hàng 100, 200và 300. Bạn tôi cũng đã buộc phải theo thứ tự của cột: z, y, x.
Tạo dữ liệu gấu trúc với danh sách
Một cách khác để tạo Pandas DataFrame là sử dụng list những từ điển :
>> >
>> >l = [ {' x ': 1, ' y ': 2, ' z ': 100} ,
... {' x ': 2, ' y ': 4, ' z ': 100} ,
... {' x ': 3, ' y ': 8, ' z ': 100} ]
>> >pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
Một lần nữa, khóa từ điển là nhãn cột và giá trị từ điển là giá trị tài liệu trong DataFrame .
Bạn cũng hoàn toàn có thể sử dụng list lồng nhau hoặc list những list làm giá trị tài liệu. Nếu bạn làm vậy, thì nên chỉ định rõ ràng những nhãn của cột, hàng hoặc cả hai khi bạn tạo DataFrame :
>> >
>> >l = [ [1, 2, 100] ,
... [2, 4, 100] ,
... [3, 8, 100] ]
>> >pd.DataFrame(l, columns=[' x ', ' y ', ' z '] )
x y z
0 1 2 100
1 2 4 100
2 3 8 100
Đó là cách bạn hoàn toàn có thể sử dụng list lồng nhau để tạo Pandas DataFrame. Bạn cũng hoàn toàn có thể sử dụng list những bộ giá trị theo cách tựa như. Để làm như vậy, chỉ cần sửa chữa thay thế những list lồng nhau trong ví dụ trên bằng những bộ giá trị .
Tạo dữ liệu gấu trúc với Mảng NumPy
Bạn có thể truyền mảng NumPy hai chiều cho hàm DataFrametạo giống như cách bạn làm với danh sách:
>> >
>> >arr = np.array( [ [1, 2, 100] ,
... [2, 4, 100] ,
... [3, 8, 100] ] )
>> >df_ = pd.DataFrame(arr, columns=[' x ', ' y ', ' z '] )
>> >df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100
Mặc dù ví dụ này trông gần giống với cách triển khai danh sách lồng nhau ở trên, nhưng nó có một ưu điểm: Bạn có thể chỉ định tham số tùy chọn copy.
Khi copyđược đặt thành False(cài đặt mặc định), dữ liệu từ mảng NumPy sẽ không được sao chép. Điều này có nghĩa là dữ liệu gốc từ mảng được gán cho Pandas DataFrame. Nếu bạn sửa đổi mảng, thì DataFrame của bạn cũng sẽ thay đổi:
>> >
>> >arr[0, 0] = 1000
>> >df_
x y z
0 1000 2 100
1 2 4 100
2 3 8 100
Như bạn có thể thấy, khi bạn thay đổi mục đầu tiên arr, bạn cũng sửa đổi df_.
Lưu ý : Việc không sao chép những giá trị tài liệu hoàn toàn có thể giúp bạn tiết kiệm ngân sách và chi phí đáng kể thời hạn và sức mạnh giải quyết và xử lý khi thao tác với những tập dữ liệu lớn .
Nếu hành vi này không phải là những gì bạn muốn, thì bạn nên chỉ định copy=Truetrong hàm DataFrametạo. Bằng cách đó, df_sẽ được tạo với một bản sao của các giá trị từ arrthay vì các giá trị thực tế.
Tạo dữ liệu gấu trúc từ tệp
Bạn hoàn toàn có thể lưu và tải tài liệu và nhãn từ Pandas DataFrame đến và từ một số ít loại tệp, gồm có CSV, Excel, SQL, JSON, v.v. Đây là một tính năng rất can đảm và mạnh mẽ .
Bạn có thể lưu DataFrame ứng viên công việc của mình vào tệp CSV với .to_csv():
>> >
>> >df.to_csv(' data.csv ')
Câu lệnh trên sẽ tạo ra một tệp CSV được gọi data.csvtrong thư mục làm việc của bạn:
,name,city,age,py-score
101,Xavier,Mexico City,41,88.0
102,Ann,Toronto,28,79.0
103,Jana,Prague,33,81.0
104,Yi,Shanghai,34,80.0
105,Robin,Manchester,38,68.0
106,Amal,Cairo,31,61.0
107,Nori,Osaka,37,84.0
Giờ bạn đã có tệp CSV chứa dữ liệu, bạn có thể tải tệp đó bằng read_csv():
>> >
>> >pd.read_csv(' data.csv ', index_col=0)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
Đó là cách bạn lấy Pandas DataFrame từ một tệp. Trong trường hợp này, index_col=0chỉ định rằng các nhãn hàng nằm trong cột đầu tiên của tệp CSV.
Truy xuất nhãn và dữ liệu
Bây giờ bạn đã tạo DataFrame của mình, bạn hoàn toàn có thể mở màn truy xuất thông tin từ nó. Với Pandas, bạn hoàn toàn có thể triển khai những hành vi sau :
- Truy xuất và sửa đổi nhãn hàng và cột dưới dạng chuỗi
- Biểu diễn dữ liệu dưới dạng mảng NumPy
- Kiểm tra và điều chỉnh các loại dữ liệu
- Phân tích kích thước của
DataFramecác đối tượng
Pandas DataFrame Labels as Sequences
Bạn có thể lấy nhãn hàng của DataFrame với .indexvà nhãn cột của nó với .columns:
>> >
>> >df.index
Int64Index ( [ 1, 2, 3, 4, 5, 6, 7 ], dtype = ' int64 ' )
>> >df.columns
Index ( [ ' name ', ' city ', ' age ', ' py-score ' ], dtype = ' object ' )
Bây giờ bạn có nhãn hàng và cột là những loại chuỗi đặc biệt quan trọng. Như bạn hoàn toàn có thể làm với bất kể chuỗi Python nào khác, bạn hoàn toàn có thể nhận được một mục duy nhất :
>> >
>> >df.columns[1]
' city '
Ngoài việc trích xuất một mục đơn cử, bạn hoàn toàn có thể vận dụng những thao tác trình tự khác, gồm có cả việc lặp qua những nhãn của hàng hoặc cột. Tuy nhiên, điều này hiếm khi thiết yếu vì Pandas cung ứng những cách khác để lặp qua DataFrames mà bạn sẽ thấy trong phần sau .
Bạn cũng hoàn toàn có thể sử dụng giải pháp này để sửa đổi những nhãn :
>> >
>> >df.index = np.arange(10, 17)
>> >df.index
Int64Index ( [ 10, 11, 12, 13, 14, 15, 16 ], dtype = ' int64 ' )
>> >df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
Trong ví dụ này, bạn sử dụng numpy.arange()để tạo một chuỗi nhãn hàng mới chứa các số nguyên từ 10đến 16. Để tìm hiểu thêm arange(), hãy xem NumPy arange (): Cách sử dụng np.arange () .
Hãy nhớ rằng nếu bạn cố gắng sửa đổi một mục cụ thể của .indexhoặc .columns, thì bạn sẽ nhận được TypeError.
Dữ liệu dưới dạng Mảng NumPy
Đôi khi bạn có thể muốn trích xuất dữ liệu từ Pandas DataFrame mà không có nhãn của nó. Để nhận mảng NumPy với dữ liệu chưa được gắn nhãn, bạn có thể sử dụng .to_numpy()hoặc .values:
>> >
>> >df.to_numpy( )
array ( [ [ ' Xavier ', ' Mexico City ', 41, 88.0 ] ,
[ ' Ann ', ' Toronto ', 28, 79.0 ] ,
[ ' Jana ', ' Prague ', 33, 81.0 ] ,
[ ' Yi ', ' Shanghai ', 34, 80.0 ] ,
[ ' Robin ', ' Manchester ', 38, 68.0 ] ,
[ ' Amal ', ' Cairo ', 31, 61.0 ] ,
[ ' Nori ', ' Osaka ', 37, 84.0 ] ], dtype = object )
Cả hai .to_numpy()và .valuescông việc tương tự, và cả hai đều trở lại một mảng với các dữ liệu từ các Pandas DataFrame NumPy:
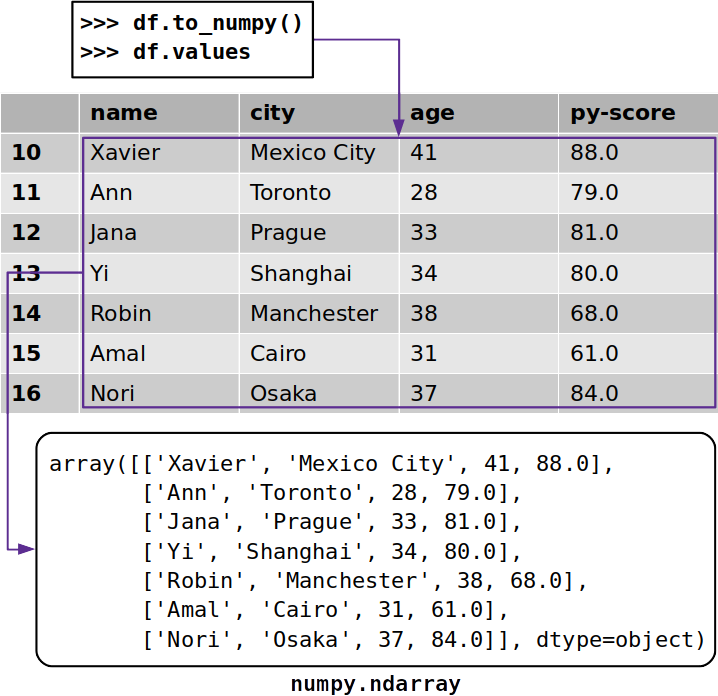
Tài liệu Pandas đề xuất sử dụng .to_numpy()vì tính linh hoạt được cung cấp bởi hai tham số tùy chọn:
dtype: Sử dụng tham số này để chỉ định kiểu dữ liệu của mảng kết quả. Nó được đặt thànhNonetheo mặc định.copy: Đặt tham số này thànhFalsenếu bạn muốn sử dụng dữ liệu gốc từ DataFrame. Đặt nó thànhTruenếu bạn muốn tạo một bản sao dữ liệu.
Tuy nhiên, nó .valuesđã tồn tại lâu hơn nhiều so với .to_numpy()những gì đã được giới thiệu trong phiên bản Pandas 0.24.0. Điều đó có nghĩa là bạn có thể sẽ thấy .valuesthường xuyên hơn, đặc biệt là trong mã cũ hơn.
Loại dữ liệu
Các loại những giá trị tài liệu, hay còn gọi là kiểu tài liệu hoặc dtypes, rất quan trọng vì họ xác lập dung tích bộ nhớ sử dụng DataFrame của bạn, cũng như vận tốc đo lường và thống kê của nó và mức độ đúng chuẩn .
Gấu trúc nhờ vào rất nhiều vào kiểu tài liệu NumPy. Tuy nhiên, Pandas 1.0 đã trình làng 1 số ít loại bổ trợ :
BooleanDtypevàBooleanArrayhỗ trợ các giá trị Boolean bị thiếu và lôgic ba giá trị Kleene .StringDtypevàStringArrayđại diện cho một loại chuỗi chuyên dụng.
Bạn có thể lấy các kiểu dữ liệu cho từng cột của Pandas DataFrame bằng .dtypes:
>> >
>> >df.dtypes
name object
city object
age int64
py-score float64
dtype : object
Như bạn có thể thấy, .dtypestrả về một Seriesđối tượng có tên cột làm nhãn và kiểu dữ liệu tương ứng dưới dạng giá trị.
Nếu bạn muốn sửa đổi kiểu dữ liệu của một hoặc nhiều cột, thì bạn có thể sử dụng .astype():
>> >
>> >df_ = df.astype(dtype={' age ': np.int32, ' py-score ': np.float32} )
>> >df_.dtypes
name object
city object
age int32
py-score float32
dtype : object
Tham số bắt buộc quan trọng nhất và duy nhất của .astype()là dtype. Nó mong đợi một kiểu dữ liệu hoặc từ điển. Nếu bạn chuyển từ điển, thì các khóa là tên cột và các giá trị là kiểu dữ liệu tương ứng mong muốn của bạn.
Như bạn có thể thấy, các kiểu dữ liệu cho các cột agevà py-scoretrong DataFrame dfđều int64, đại diện cho 64-bit (hoặc 8-byte) số nguyên. Tuy nhiên, df_cũng cung cấp một kiểu dữ liệu số nguyên 32 bit (4 byte) nhỏ hơn được gọi int32.
Dữ liệu gấu trúc
Các thuộc tính .ndim, .sizevà .shapetrả lại số kích thước, số lượng các giá trị dữ liệu trên mỗi chiều, và tổng số giá trị dữ liệu, tương ứng:
>> >
>> >df_.ndim
2
>> >df_.shape
( 7, 4 )
>> >df_.size
28
DataFramecác phiên bản có hai thứ nguyên (hàng và cột), do đó, .ndimtrả về 2. Mặt khác, một Seriesđối tượng chỉ có một chiều duy nhất, vì vậy trong trường hợp đó, .ndimsẽ quay trở lại 1.
Các .shapelợi nhuận thuộc tính một tuple với số hàng (trong trường hợp này 7) và số cột ( 4). Cuối cùng, .sizetrả về một số nguyên bằng số giá trị trong DataFrame ( 28).
Bạn thậm chí có thể kiểm tra dung lượng bộ nhớ được sử dụng bởi mỗi cột với .memory_usage():
>> >
>> >df_.memory_usage( )
Index 56
name 56
city 56
age 28
py-score 28
dtype : int64
Như bạn có thể thấy, .memory_usage()trả về một Chuỗi với tên cột làm nhãn và mức sử dụng bộ nhớ tính bằng byte dưới dạng giá trị dữ liệu. Nếu bạn muốn loại trừ việc sử dụng bộ nhớ của cột chứa các nhãn hàng, thì hãy chuyển đối số tùy chọn index=False.
Trong ví dụ trên, hai cột cuối cùng agevà py-scoresử dụng 28 byte bộ nhớ mỗi cột . Đó là bởi vì các cột này có bảy giá trị, mỗi giá trị là một số nguyên chiếm 32 bit hoặc 4 byte. Bảy số nguyên nhân với 4 byte, mỗi số tương đương với tổng số 28 byte sử dụng bộ nhớ.
Truy cập và sửa đổi dữ liệu
Bạn đã học cách lấy một hàng hoặc cột cụ thể của Pandas DataFrame làm Seriesđối tượng:
>> >
>> >df[' name ']
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name : name, dtype : object
>> >df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name : 10, dtype : object
Trong ví dụ đầu tiên, bạn truy cập cột namenhư cách bạn truy cập một phần tử từ từ điển, bằng cách sử dụng nhãn của nó làm khóa. Nếu nhãn cột là một mã định danh Python hợp lệ, thì bạn cũng có thể sử dụng ký hiệu dấu chấm để truy cập cột. Trong ví dụ thứ hai, bạn sử dụng .loc[]để lấy hàng theo nhãn của nó 10,.
Nhận dữ liệu với người truy cập
Ngoài trình truy cập .loc[]mà bạn có thể sử dụng để lấy các hàng hoặc cột theo nhãn của chúng, Pandas cung cấp trình .iloc[]truy cập, truy xuất một hàng hoặc cột theo chỉ mục số nguyên của nó. Trong hầu hết các trường hợp, bạn có thể sử dụng một trong hai cách sau:
>> >
>> >df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name : 10, dtype : object
>> >df.iloc[0]
name Xavier
city Mexico City
age 41
py-score 88
Name : 10, dtype : object
df.loc[10]trả về hàng có nhãn 10. Tương tự, df.iloc[0]trả về hàng có chỉ mục dựa trên 0 0, là hàng đầu tiên. Như bạn có thể thấy, cả hai câu lệnh đều trả về cùng một hàng như một Seriesđối tượng.
Tổng cộng Pandas có bốn người truy vấn :
-
.loc[]chấp nhận các nhãn của hàng và cột và trả về Chuỗi hoặc Dữ liệu. Bạn có thể sử dụng nó để lấy toàn bộ hàng hoặc cột, cũng như các phần của chúng. -
.iloc[]chấp nhận các chỉ số dựa trên 0 của các hàng và cột và trả về Series hoặc DataFrames. Bạn có thể sử dụng nó để lấy toàn bộ hàng hoặc cột hoặc các phần của chúng. -
.at[]chấp nhận nhãn của các hàng và cột và trả về một giá trị dữ liệu duy nhất. -
.iat[]chấp nhận các chỉ số dựa trên 0 của các hàng và cột và trả về một giá trị dữ liệu duy nhất.
Trong số này, .loc[]và .iloc[]đặc biệt mạnh mẽ. Chúng hỗ trợ cắt và lập chỉ mục kiểu NumPy . Bạn có thể sử dụng chúng để truy cập một cột:
>> >
>> >df.loc[ :, ' city ']
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name : city, dtype : object
>> >df.iloc[ :, 1]
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name : city, dtype : object
df.loc[:, 'city']trả về cột city. Cấu trúc lát cắt ( :) ở vị trí nhãn hàng có nghĩa là tất cả các hàng phải được đưa vào. df.iloc[:, 1]trả về cùng một cột vì chỉ mục dựa trên 0 1tham chiếu đến cột thứ hai city,.
Cũng giống như bạn hoàn toàn có thể làm với NumPy, bạn hoàn toàn có thể cung ứng những lát cùng với list hoặc mảng thay vì chỉ số để có nhiều hàng hoặc cột :
>> >
>> >df.loc[11:15, [' name ', ' city '] ]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal Cairo
>> >df.iloc[1:6, [0, 1] ]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal Cairo
Lưu ý : Không sử dụng bộ giá trị thay vì list hoặc mảng số nguyên để lấy những hàng hoặc cột thường thì. Tuples được dành riêng để đại diện thay mặt cho nhiều thứ nguyên trong NumPy và Pandas, cũng như lập chỉ mục phân cấp hoặc đa cấp trong Pandas .
Trong ví dụ này, bạn sử dụng :
- Lát để lấy các hàng có nhãn
11thông qua15, tương đương với các chỉ số1thông qua5 - Liệt kê để lấy các cột
namevàcitytương đương với các chỉ số0và1
Cả hai câu lệnh đều trả về một Pandas DataFrame với giao của năm hàng và hai cột mong ước .
Điều này dẫn đến sự khác biệt rất quan trọng giữa .loc[]và .iloc[]. Như bạn có thể nhìn thấy từ ví dụ trước, khi bạn vượt qua các nhãn hàng 11:15để .loc[], bạn sẽ có được các hàng 11thông qua 15. Tuy nhiên, khi bạn chuyển chỉ số hàng 1:6đến .iloc[], bạn chỉ nhận được các hàng có chỉ số 1đi qua 5.
Lý do bạn chỉ nhận được các chỉ số 1thông qua 5là, với .iloc[], chỉ số dừng của một lát cắt là độc quyền , có nghĩa là nó bị loại trừ khỏi các giá trị trả về. Điều này phù hợp với chuỗi Python và mảng NumPy. Với .loc[]Tuy nhiên, cả hai bắt đầu và dừng lại chỉ số là bao gồm , có nghĩa là họ được bao gồm với các giá trị trả lại.
Bạn có thể bỏ qua các hàng và cột .iloc[]theo cách tương tự với cách cắt các bộ giá trị, danh sách và mảng NumPy:
>> >
>> >df.iloc[1:6:2, 0]
11 Ann
13 Yi
15 Amal
Name : name, dtype : object
Trong ví dụ này, bạn chỉ định các chỉ số hàng mong muốn với lát cắt 1:6:2. Điều này có nghĩa là bạn bắt đầu với hàng có chỉ mục 1(hàng thứ hai), dừng lại trước hàng có chỉ mục 6(hàng thứ bảy) và bỏ qua mọi hàng thứ hai.
Thay vì sử dụng cấu trúc cắt, bạn cũng có thể sử dụng lớp Python được tích hợp sẵn slice(), cũng như numpy.s_[]hoặc pd.IndexSlice[]:
>> >
>> >df.iloc[slice(1, 6, 2), 0]
11 Ann
13 Yi
15 Amal
Name : name, dtype : object
>> >df.iloc[np.s_[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name : name, dtype : object
>> >df.iloc[pd.IndexSlice[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name : name, dtype : object
Bạn hoàn toàn có thể thấy một trong những cách tiếp cận này thuận tiện hơn những cách khác tùy thuộc vào trường hợp của bạn .
Có thể sử dụng .loc[]và .iloc[]lấy các giá trị dữ liệu cụ thể. Tuy nhiên, khi bạn chỉ cần một giá trị duy nhất, Pandas khuyên bạn nên sử dụng các trình truy cập chuyên dụng .at[]và .iat[]:
>> >
>> >df.at[12, ' name ']
' Jana '
>> >df.iat[2, 0]
' Jana '
Ở đây, bạn đã sử dụng .at[]để lấy tên của một ứng cử viên bằng cách sử dụng các nhãn cột và hàng tương ứng của nó. Bạn cũng đã sử dụng .iat[]để truy xuất cùng một tên bằng cách sử dụng các chỉ số cột và hàng của nó.
Thiết lập dữ liệu với trình truy cập
Bạn hoàn toàn có thể sử dụng trình truy vấn để sửa đổi những phần của Pandas DataFrame bằng cách chuyển một chuỗi Python, mảng NumPy hoặc giá trị đơn lẻ :
>> >
>> >df.loc[ :, ' py-score ']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name : py-score, dtype : float64
>> >df.loc[ :13, ' py-score '] = [40, 50, 60, 70]
>> >df.loc[14:, ' py-score '] = 0
>> >df[' py-score ']
10 40.0
11 50.0
12 60.0
13 70.0
14 0.0
15 0.0
16 0.0
Name : py-score, dtype : float64
Câu lệnh df.loc[:13, 'py-score'] = [40, 50, 60, 70]sửa đổi bốn mục đầu tiên (từ hàng 10đến 13) trong cột py-scorebằng cách sử dụng các giá trị từ danh sách được cung cấp của bạn. Sử dụng df.loc[14:, 'py-score'] = 0đặt các giá trị còn lại trong cột này thành 0.
Ví dụ sau cho thấy rằng bạn có thể sử dụng các chỉ số phủ định .iloc[]để truy cập hoặc sửa đổi dữ liệu:
>> >
>> >df.iloc[ :, -1] = np.array( [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0] )
>> >df[' py-score ']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name : py-score, dtype : float64
Trong ví dụ này, bạn đã truy cập và sửa đổi cột cuối cùng ( 'py-score'), tương ứng với chỉ mục cột số nguyên -1. Hành vi này phù hợp với chuỗi Python và mảng NumPy.
Chèn và Xóa dữ liệu
Pandas phân phối một số ít kỹ thuật thuận tiện để chèn và xóa hàng hoặc cột. Bạn hoàn toàn có thể chọn trong số họ dựa trên tình hình và nhu yếu của bạn .
Chèn và xóa hàng
Hãy tưởng tượng bạn muốn thêm một người mới vào danh sách ứng viên tuyển dụng của mình. Bạn có thể bắt đầu bằng cách tạo một Seriesđối tượng mới đại diện cho ứng cử viên mới này:
>> >
>> >john = pd.Series(data=[' John ', ' Boston ', 34, 79] ,
... index=df.columns, name=17)
>> >john
name John
city Boston
age 34
py-score 79
Name : 17, dtype : object
>> >john.name
17
Đối tượng mới có các nhãn tương ứng với các nhãn cột từ df. Đó là lý do tại sao bạn cần index=df.columns.
Bạn có thể thêm johndưới dạng một hàng mới vào cuối dfbằng .append():
>> >
>> >df = df.append(john)
>> >df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
17 John Boston 34 79.0
Tại đây, .append()trả về Pandas DataFrame với hàng mới được thêm vào. Lưu ý cách Pandas sử dụng thuộc tính john.name, là giá trị 17, để chỉ định nhãn cho hàng mới.
Bạn đã thêm một hàng mới với một lệnh gọi đến .append()và bạn có thể xóa hàng đó bằng một lệnh gọi tới .drop():
>> >
>> >df = df.drop(labels=[17] )
>> >df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
Tại đây, .drop()xóa các hàng được chỉ định với tham số labels. Theo mặc định, nó trả về Pandas DataFrame với các hàng được chỉ định đã bị xóa. Nếu bạn vượt qua inplace=True, thì DataFrame ban đầu sẽ được sửa đổi và bạn sẽ nhận được Nonedưới dạng giá trị trả về.
Chèn và Xóa các Cột
Cách đơn thuần nhất để chèn một cột trong Pandas DataFrame là làm theo cùng một tiến trình mà bạn sử dụng khi thêm một mục vào từ điển. Đây là cách bạn hoàn toàn có thể thêm một cột chứa điểm của ứng viên của bạn trong một bài kiểm tra JavaScript :
>> >
>> >df[' js-score '] = np.array( [71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0] )
>>>
Xem thêm: Hướng dẫn và ví dụ String trong Python
df
name city age py-score js-score
10 Xavier Mexico City 41 88.0 71.0
11 Ann Toronto 28 79.0 95.0
12 Jana Prague 33 81.0 88.0
13 Yi Shanghai 34 80.0 79.0
14 Robin Manchester 38 68.0 91.0
15 Amal Cairo 31 61.0 91.0
16 Nori Osaka 37 84.0 80.0
Bây giờ DataFrame ban đầu có thêm một cột js-score, ở cuối.
Bạn không cần phải phân phối một chuỗi giá trị khá đầy đủ. Bạn hoàn toàn có thể thêm một cột mới với một giá trị duy nhất :
>> >
>> >df[' total-score '] = 0.0
>> >df
name city age py-score js-score total-score
10 Xavier Mexico City 41 88.0 71.0 0.0
11 Ann Toronto 28 79.0 95.0 0.0
12 Jana Prague 33 81.0 88.0 0.0
13 Yi Shanghai 34 80.0 79.0 0.0
14 Robin Manchester 38 68.0 91.0 0.0
15 Amal Cairo 31 61.0 91.0 0.0
16 Nori Osaka 37 84.0 80.0 0.0
DataFrame dfhiện có một cột bổ sung chứa các số không.
Nếu bạn đã sử dụng từ điển trước đây, thì cách chèn cột này có thể quen thuộc với bạn. Tuy nhiên, nó không cho phép bạn chỉ định vị trí của cột mới. Nếu vị trí của cột mới là quan trọng, thì bạn có thể sử dụng .insert()thay thế:
>> >
>> >df.insert(loc=4, column=' django-score ',
... value=np.array( [86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0] ) )
>> >df
name city age py-score django-score js-score total-score
10 Xavier Mexico City 41 88.0 86.0 71.0 0.0
11 Ann Toronto 28 79.0 81.0 95.0 0.0
12 Jana Prague 33 81.0 78.0 88.0 0.0
13 Yi Shanghai 34 80.0 88.0 79.0 0.0
14 Robin Manchester 38 68.0 74.0 91.0 0.0
15 Amal Cairo 31 61.0 70.0 91.0 0.0
16 Nori Osaka 37 84.0 81.0 80.0 0.0
Bạn vừa chèn một cột khác có điểm của bài kiểm tra Django . Tham số locxác định vị trí hoặc chỉ mục dựa trên 0 của cột mới trong Pandas DataFrame. columnđặt nhãn của cột mới và valuechỉ định các giá trị dữ liệu để chèn.
Bạn có thể xóa một hoặc nhiều cột khỏi Pandas DataFrame giống như cách bạn làm với từ điển Python thông thường, bằng cách sử dụng delcâu lệnh :
>> >
>> >del df[' total-score ']
>> >df
name city age py-score django-score js-score
10 Xavier Mexico City 41 88.0 86.0 71.0
11 Ann Toronto 28 79.0 81.0 95.0
12 Jana Prague 33 81.0 78.0 88.0
13 Yi Shanghai 34 80.0 88.0 79.0
14 Robin Manchester 38 68.0 74.0 91.0
15 Amal Cairo 31 61.0 70.0 91.0
16 Nori Osaka 37 84.0 81.0 80.0
Bây giờ bạn có dfmà không có cột total-score. Một điểm tương đồng khác với từ điển là khả năng sử dụng .pop(), loại bỏ cột được chỉ định và trả lại cột đó. Điều đó có nghĩa là bạn có thể làm điều gì đó giống như df.pop('total-score')thay vì sử dụng del.
Bạn cũng có thể xóa một hoặc nhiều cột .drop()như bạn đã làm trước đó với các hàng. Một lần nữa, bạn cần chỉ định nhãn của các cột mong muốn với labels. Ngoài ra, khi bạn muốn loại bỏ các cột, bạn cần cung cấp đối số axis=1:
>> >
>> >df = df.drop(labels=' age ', axis=1)
>> >df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
Bạn đã xóa cột agekhỏi DataFrame của mình.
Theo mặc định, .drop()trả về DataFrame không có các cột được chỉ định trừ khi bạn vượt qua inplace=True.
Áp dụng các phép toán số học
Bạn có thể áp dụng các phép toán số học cơ bản như cộng, trừ, nhân và chia cho Pandas Seriesvà DataFramecác đối tượng giống như cách bạn làm với mảng NumPy :
>> >
>> >df[' py-score '] + df[' js-score ']
10 159.0
11 174.0
12 169.0
13 159.0
14 159.0
15 152.0
16 164.0
dtype : float64
>> >df[' py-score '] / 100
10 0.88
11 0.79
12 0.81
13 0.80
14 0.68
15 0.61
16 0.84
Name : py-score, dtype : float64
Bạn có thể sử dụng kỹ thuật này để chèn một cột mới vào Pandas DataFrame. Ví dụ: hãy thử tính totalđiểm dưới dạng kết hợp tuyến tính của điểm Python, Django và JavaScript của ứng viên của bạn:
>> >
>> >df[' total '] =\
... 0.4 * df[' py-score '] + 0.3 * df[' django-score '] + 0.3 * df[' js-score ']
>> >df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
Bây giờ DataFrame của bạn có một cột với totalđiểm được tính từ điểm kiểm tra cá nhân của ứng viên của bạn. Tuyệt vời hơn nữa, bạn đã đạt được điều đó chỉ với một câu nói duy nhất!
Áp dụng các hàm NumPy và SciPy
Hầu hết các quy trình NumPy và SciPy có thể được áp dụng cho Pandas Serieshoặc DataFrameđối tượng dưới dạng đối số thay vì dưới dạng mảng NumPy. Để minh họa điều này, bạn có thể tính toán tổng điểm kiểm tra của các ứng viên bằng cách sử dụng quy trình NumPy numpy.average().
Thay vì chuyển một mảng NumPy sang numpy.average(), bạn sẽ chuyển một phần của Pandas DataFrame của mình:
>> >
>> >import numpy as np
>> >score = df.iloc[ :, 2:5]
>> >score
py-score django-score js-score
10 88.0 86.0 71.0
11 79.0 81.0 95.0
12 81.0 78.0 88.0
13 80.0 88.0 79.0
14 68.0 74.0 91.0
15 61.0 70.0 91.0
16 84.0 81.0 80.0
>> >np.average(score, axis=1,
... weights=[0.4, 0.3, 0.3] )
array ( [ 82.3, 84.4, 82.2, 82.1, 76.7, 72.7, 81.9 ] )
Hiện scoretại, biến này đề cập đến DataFrame với điểm số Python, Django và JavaScript. Bạn có thể sử dụng scorelàm đối số numpy.average()và lấy kết hợp tuyến tính của các cột với trọng số được chỉ định.
Nhưng đó không phải là tất cả! Bạn có thể sử dụng mảng NumPy được trả về average()như một cột mới của df. Trước tiên, xóa cột hiện có totalkhỏi df, sau đó nối cột mới bằng cách sử dụng average():
>> >
>> >del df[' total ']
>> >df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
>> >df[' total '] = np.average(df.iloc[ :, 2:5], axis=1,
... weights=[0.4, 0.3, 0.3] )
>> >df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
Kết quả tựa như như trong ví dụ trước, nhưng ở đây bạn đã sử dụng hàm NumPy hiện có thay vì viết mã của riêng bạn .
Sắp xếp dữ liệu gấu trúc
Bạn có thể sắp xếp một Pandas DataFrame với .sort_values():
>> >
>> >df.sort_values(by=' js-score ', ascending=False)
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9
13 Yi Shanghai 80.0 88.0 79.0 82.1
10 Xavier Mexico City 88.0 86.0 71.0 82.3
Ví dụ này sắp xếp DataFrame của bạn theo các giá trị trong cột js-score. Tham số byđặt nhãn của hàng hoặc cột để sắp xếp theo. ascendingchỉ định xem bạn muốn sắp xếp theo thứ tự tăng dần ( True) hay giảm dần ( False), thứ tự sau là cài đặt mặc định. Bạn có thể vượt qua axisđể chọn nếu bạn muốn sắp xếp hàng ( axis=0) hoặc cột ( axis=1).
Nếu bạn muốn sắp xếp theo nhiều cột, thì chỉ cần chuyển danh sách làm đối số cho byvà ascending:
>> >
>> >df.sort_values(by=[' total ', ' py-score '], ascending=[False, False] )
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
10 Xavier Mexico City 88.0 86.0 71.0 82.3
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
Trong trường hợp này, DataFrame được sắp xếp theo cột total, nhưng nếu hai giá trị giống nhau, thì thứ tự của chúng được xác định bởi các giá trị từ cột py-score.
Tham số tùy chọn inplacecũng có thể được sử dụng với .sort_values(). Nó được đặt thành Falsetheo mặc định, đảm bảo .sort_values()trả về một Pandas DataFrame mới. Khi bạn đặt inplace=True, DataFrame hiện có sẽ được sửa đổi và .sort_values()sẽ trở lại None.
Nếu bạn đã từng nỗ lực sắp xếp những giá trị trong Excel, thì bạn hoàn toàn có thể thấy cách tiếp cận Pandas hiệu suất cao và thuận tiện hơn nhiều. Khi bạn có một lượng lớn tài liệu, Pandas hoàn toàn có thể tiêu biểu vượt trội hơn đáng kể so với Excel .
Để biết thêm thông tin về cách sắp xếp trong Gấu trúc, hãy xem Sắp xếp theo gấu trúc : Hướng dẫn sắp xếp tài liệu bằng Python của bạn .
Lọc dữ liệu
Lọc tài liệu là một tính năng can đảm và mạnh mẽ khác của Pandas. Nó hoạt động giải trí tương tự như như lập chỉ mục với mảng Boolean trong NumPy .
Nếu bạn áp dụng một số hoạt động logic trên một Seriesđối tượng, thì bạn sẽ nhận được một Chuỗi khác với các giá trị Boolean Truevà False:
>> >
>> >filter_ = df[' django-score '] > = 80
>> >filter_
10 True
11 True
12 False
13 True
14 False
15 False
16 True
Name : django-score, dtype : bool
Trong trường hợp này, df['django-score'] >= 80trả về Truecho những hàng có điểm Django lớn hơn hoặc bằng 80. Nó trả về Falsecho những hàng có điểm Django nhỏ hơn 80.
Bây giờ bạn có Chuỗi filter_chứa đầy dữ liệu Boolean. Biểu thức df[filter_]trả về một Pandas DataFrame với các hàng từ dfđó tương ứng với Truetrong filter_:
>> >
>> >df[filter_]
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
Như bạn có thể thấy, filter_[10], filter_[11], filter_[13], và filter_[16]là True, do đó df[filter_]chứa các hàng với các nhãn này. Mặt khác, filter_[12], filter_[14], và filter_[15]là False, vì vậy các hàng tương ứng không xuất hiện trong df[filter_].
Bạn hoàn toàn có thể tạo những biểu thức rất can đảm và mạnh mẽ và phức tạp bằng cách tích hợp những phép toán logic với những toán tử sau :
NOT(~)AND(&)OR(|)XOR(^)
Ví dụ: bạn có thể nhận được DataFrame với các ứng viên có py-scorevà js-scorelớn hơn hoặc bằng 80:
>> >
>> >df[ (df[' py-score '] > = 80) và (df[' js-score '] > = 80) ]
name city py-score django-score js-score total
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9
Biểu thức (df['py-score'] >= 80) & (df['js-score'] >= 80)trả về một Chuỗi có Truetrong các hàng có cả hai py-scorevà js-scorelớn hơn hoặc bằng 80 và Falsecác hàng khác. Trong trường hợp này, chỉ các hàng có nhãn 12và 16thỏa mãn cả hai điều kiện.
Bạn cũng hoàn toàn có thể vận dụng những quy trình tiến độ logic NumPy thay vì những toán tử .
Đối với một số thao tác yêu cầu lọc dữ liệu, sẽ thuận tiện hơn khi sử dụng .where(). Nó thay thế các giá trị ở các vị trí mà điều kiện đã cung cấp không được thỏa mãn:
>> >
>> >df[' django-score '].where(cond=df[' django-score '] > = 80, other=0.0)
10 86.0
11 81.0
12 0.0
13 88.0
14 0.0
15 0.0
16 81.0
Name : django-score, dtype : float64
Trong ví dụ này, điều kiện là df['django-score'] >= 80. Các giá trị của DataFrame hoặc Chuỗi .where()sẽ được giữ nguyên khi có điều kiện Truevà sẽ được thay thế bằng giá trị của other(trong trường hợp này 0.0) khi có điều kiện False.
Xác định thống kê dữ liệu
Pandas cung cấp nhiều phương pháp thống kê cho DataFrames. Bạn có thể nhận thống kê cơ bản cho các cột số của Pandas DataFrame với .describe():
>> >
>> >df.describe( )
py-score django-score js-score total
count 7.000000 7.000000 7.000000 7.000000
mean 77.285714 79.714286 85.000000 80.328571
std 9.446592 6.343350 8.544004 4.101510
min 61.000000 70.000000 71.000000 72.700000
25 % 73.500000 76.000000 79.500000 79.300000
50 % 80.000000 81.000000 88.000000 82.100000
75 % 82.500000 83.500000 91.000000 82.250000
max 88.000000 88.000000 95.000000 84.400000
Tại đây, .describe()trả về một DataFrame mới với số hàng được chỉ định bởi count, cũng như giá trị trung bình, độ lệch chuẩn, tối thiểu, tối đa và phần tư của các cột.
Nếu bạn muốn nhận thống kê cụ thể cho một số hoặc tất cả các cột của mình, thì bạn có thể gọi các phương thức như .mean()hoặc .std():
>> >
>> >df.mean( )
py-score 77.285714
django-score 79.714286
js-score 85.000000
total 80.328571
dtype : float64
>> >df[' py-score '].mean( )
77.28571428571429
>> >df.std( )
py-score 9.446592
django-score 6.343350
js-score 8.544004
total 4.101510
dtype : float64
>> >df[' py-score '].std( )
9.446591726019244
Khi được áp dụng cho Pandas DataFrame, các phương pháp này trả về Chuỗi với kết quả cho mỗi cột. Khi được áp dụng cho một Seriesđối tượng hoặc một cột của DataFrame, các phương thức này sẽ trả về giá trị vô hướng .
Để tìm hiểu và khám phá thêm về giám sát thống kê với Gấu trúc, hãy xem Thống kê miêu tả với Python và NumPy, SciPy và Pandas : Tương quan với Python .
Xử lý dữ liệu bị thiếu
Dữ liệu bị thiếu là rất phổ cập trong khoa học dữ liệu và học máy. Nhưng đừng khi nào sợ hãi ! Pandas có những tính năng rất mạnh để thao tác với tài liệu bị thiếu. Trên trong thực tiễn, tài liệu của nó có hàng loạt phần dành riêng để thao tác với tài liệu bị thiếu .
Gấu trúc thường đại diện cho dữ liệu bị thiếu bằng giá trị NaN (không phải số) . Trong Python, bạn có thể nhận NaN với float('nan'), math.nanhoặc numpy.nan. Bắt đầu với Pandas 1.0, loại mới thích BooleanDtype, Int8Dtype, Int16Dtype, Int32Dtype, và Int64Dtypesử dụng pandas.NAnhư một giá trị bị mất tích.
Dưới đây là ví dụ về Pandas DataFrame bị thiếu giá trị :
>> >
>> >df_ = pd.DataFrame( {' x ': [1, 2, np.nan, 4] } )
>> >df_
x
0 1.0
1 2.0
2 NaN
3 4.0
Biến df_tham chiếu đến DataFrame với một cột xvà bốn giá trị. Giá trị thứ ba nanđược coi là bị thiếu theo mặc định.
Tính toán với dữ liệu bị thiếu
Nhiều phương thức Pandas bỏ qua nancác giá trị khi thực hiện tính toán trừ khi chúng được hướng dẫn rõ ràng là không :
>> >
>> >df_.mean( )
x 2.333333
dtype : float64
>> >df_.mean(skipna=False)
x NaN
dtype : float64
Trong ví dụ đầu tiên, df_.mean()tính giá trị trung bình mà không tính đến NaN(giá trị thứ ba). Nó chỉ mất 1.0, 2.0và 4.0và trả trung bình của họ, đó là 2,33.
Tuy nhiên, nếu bạn hướng dẫn .mean()không bỏ qua nancác giá trị với skipna=False, thì nó sẽ xem xét chúng và trả về nannếu có bất kỳ giá trị nào bị thiếu trong số dữ liệu.
Làm đầy dữ liệu bị thiếu
Pandas có một số tùy chọn để điền hoặc thay thế các giá trị bị thiếu bằng các giá trị khác. Một trong những phương pháp thuận tiện nhất là .fillna(). Bạn có thể sử dụng nó để thay thế các giá trị bị thiếu bằng:
- Các giá trị được chỉ định
- Các giá trị trên giá trị bị thiếu
- Các giá trị dưới giá trị bị thiếu
Đây là cách bạn hoàn toàn có thể vận dụng những tùy chọn được đề cập ở trên :
>> >
>> >df_.fillna(value=0)
x
0 1.0
1 2.0
2 0.0
3 4.0
>> >df_.fillna(method=' ffill ')
x
0 1.0
1 2.0
2 2.0
3 4.0
>> >df_.fillna(method=' bfill ')
x
0 1.0
1 2.0
2 4.0
3 4.0
Trong ví dụ đầu tiên, hãy .fillna(value=0)thay thế giá trị bị thiếu bằng 0.0mà bạn đã chỉ định value. Trong ví dụ thứ hai, .fillna(method='ffill')thay thế giá trị bị thiếu bằng giá trị ở trên nó, giá trị này 2.0. Trong ví dụ thứ ba, .fillna(method='bfill')sử dụng giá trị bên dưới giá trị bị thiếu, đó là 4.0.
Một lựa chọn phổ biến khác là áp dụng phép nội suy và thay thế các giá trị bị thiếu bằng các giá trị được nội suy. Bạn có thể làm điều này với .interpolate():
>> >
>> >df_.interpolate( )
x
0 1.0
1 2.0
2 3.0
3 4.0
Như bạn có thể thấy, hãy .interpolate()thay thế giá trị bị thiếu bằng một giá trị nội suy.
Bạn cũng có thể sử dụng tham số tùy chọn inplacevới .fillna(). Làm như vậy sẽ:
- Tạo và trả về DataFrame mới khi
inplace=False - Sửa đổi DataFrame hiện có và trả lại
Nonekhiinplace=True
Cài đặt mặc định cho inplacelà False. Tuy nhiên, inplace=Truecó thể rất hữu ích khi bạn đang làm việc với một lượng lớn dữ liệu và muốn ngăn việc sao chép không cần thiết và không hiệu quả.
Xóa hàng và cột có dữ liệu bị thiếu
Trong một số trường hợp nhất định, bạn có thể muốn xóa các hàng hoặc thậm chí các cột có giá trị bị thiếu. Bạn có thể làm điều này với .dropna():
>> >
>> >df_.dropna( )
x
0 1.0
1 2.0
3 4.0
Trong trường hợp này, .dropna()chỉ cần xóa hàng có nan, bao gồm cả nhãn của hàng đó. Nó cũng có tham số tùy chọn inplace, hoạt động giống như với .fillna()và .interpolate().
Lặp lại trên một dữ liệu gấu trúc
Như bạn đã học trước đó, các nhãn hàng và cột của DataFrame có thể được truy xuất dưới dạng chuỗi với .indexvà .columns. Bạn có thể sử dụng tính năng này để lặp lại các nhãn và lấy hoặc đặt các giá trị dữ liệu. Tuy nhiên, Pandas cung cấp một số phương pháp thuận tiện hơn để lặp lại:
.items()để lặp qua các cột.iteritems()để lặp qua các cột.iterrows()để lặp qua các hàng.itertuples()để lặp qua các hàng và nhận các bộ giá trị được đặt tên
Với .items()và .iteritems(), bạn lặp qua các cột của Pandas DataFrame. Mỗi lần lặp tạo ra một bộ dữ liệu với tên của cột và dữ liệu cột dưới dạng một Seriesđối tượng:
>> >
>> >for col_label, col in df.iteritems( ) :
... print(col_label, col, sep='\ n', end='\ n \ n')
...
name
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name : name, dtype : object
city
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name : city, dtype : object
py-score
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name : py-score, dtype : float64
django-score
10 86.0
11 81.0
12 78.0
13 88.0
14 74.0
15 70.0
16 81.0
Name : django-score, dtype : float64
js-score
10 71.0
11 95.0
12 88.0
13 79.0
14 91.0
15 91.0
16 80.0
Name : js-score, dtype : float64
total
10 82.3
11 84.4
12 82.2
13 82.1
14 76.7
15 72.7
16 81.9
Name : total, dtype : float64
Đó là cách bạn sử dụng .items()và .iteritems().
Với .iterrows(), bạn lặp lại các hàng của Pandas DataFrame. Mỗi lần lặp tạo ra một bộ giá trị với tên của hàng và dữ liệu hàng dưới dạng một Seriesđối tượng:
>> >
>> >for row_label, row in df.iterrows( ) :
... print(row_label, row, sep='\ n', end='\ n \ n')
...
10
name Xavier
city Mexico City
py-score 88
django-score 86
js-score 71
total 82.3
Name : 10, dtype : object
11
name Ann
city Toronto
py-score 79
django-score 81
js-score 95
total 84.4
Name : 11, dtype : object
12
name Jana
city Prague
py-score 81
django-score 78
js-score 88
total 82.2
Name : 12, dtype : object
13
name Yi
city Shanghai
py-score 80
django-score 88
js-score 79
total 82.1
Name : 13, dtype : object
14
name Robin
city Manchester
py-score 68
django-score 74
js-score 91
total 76.7
Name : 14, dtype : object
15
name Amal
city Cairo
py-score 61
django-score 70
js-score 91
total 72.7
Name : 15, dtype : object
16
name Nori
city Osaka
py-score 84
django-score 81
js-score 80
total 81.9
Name : 16, dtype : object
Đó là cách bạn sử dụng .iterrows().
Tương tự, .itertuples()lặp qua các hàng và trong mỗi lần lặp lại tạo ra một bộ được đặt tên với (tùy chọn) chỉ mục và dữ liệu:
>> >
>> >for row in df.loc[ :, [' name ', ' city ', ' total '] ].itertuples( ) :
... print(row)
...
Pandas ( Index = 10, name = ' Xavier ', city = ' Mexico City ', total = 82.3 )
Pandas ( Index = 11, name = ' Ann ', city = ' Toronto ', total = 84.4 )
Pandas ( Index = 12, name = ' Jana ', city = ' Prague ', total = 82.19999999999999 )
Pandas ( Index = 13, name = ' Yi ', city = ' Shanghai ', total = 82.1 )
Pandas ( Index = 14, name = ' Robin ', city = ' Manchester ', total = 76.7 )
Pandas ( Index = 15, name = ' Amal ', city = ' Cairo ', total = 72.7 )
Pandas ( Index = 16, name = ' Nori ', city = ' Osaka ', total = 81.9 )
Bạn có thể chỉ định tên của tuple đã đặt tên với tham số nameđược đặt thành 'Pandas'theo mặc định. Bạn cũng có thể chỉ định xem có bao gồm các nhãn hàng hay không index, được đặt thành Truetheo mặc định.
Làm việc với chuỗi thời gian
Gấu trúc tiêu biểu vượt trội trong việc giải quyết và xử lý chuỗi thời hạn. Mặc dù công dụng này một phần dựa trên lịch ngày và thời hạn của NumPy, nhưng Pandas cung cấp tính linh động hơn nhiều .
Tạo DataFrames với nhãn chuỗi thời gian
Trong phần này, bạn sẽ tạo Pandas DataFrame bằng cách sử dụng tài liệu nhiệt độ hàng giờ của một ngày .
Bạn hoàn toàn có thể khởi đầu bằng cách tạo một list ( hoặc bộ, mảng NumPy hoặc kiểu tài liệu khác ) với những giá trị tài liệu, sẽ là nhiệt độ hàng giờ được tính bằng độ C :
>> >
>> >temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0,
... 9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1,
... 21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]
Bây giờ bạn có biến temp_c, tham chiếu đến danh sách các giá trị nhiệt độ.
Bước tiếp theo là tạo một chuỗi ngày và giờ. Pandas cung cấp một chức năng rất tiện lợi date_range(), cho mục đích này:
>> >
>> >dt = pd.date_range(start=' 2019 - 10-27 00:00:00. 0 ', periods=24,
... freq=' H ')
>> >dt
DatetimeIndex ( [ ' 2019 - 10-27 00:00:00 ', ' 2019 - 10-27 01:00:00 ' ,
' 2019 - 10-27 02:00:00 ', ' 2019 - 10-27 03:00:00 ' ,
' 2019 - 10-27 04:00:00 ', ' 2019 - 10-27 05:00:00 ' ,
' 2019 - 10-27 06:00:00 ', ' 2019 - 10-27 07:00:00 ' ,
' 2019 - 10-27 08:00:00 ', ' 2019 - 10-27 09:00:00 ' ,
' 2019 - 10-27 10:00:00 ', ' 2019 - 10-27 11:00:00 ' ,
' 2019 - 10-27 12:00:00 ', ' 2019 - 10-27 13:00:00 ' ,
' 2019 - 10-27 14:00:00 ', ' 2019 - 10-27 15:00:00 ' ,
' 2019 - 10-27 16:00:00 ', ' 2019 - 10-27 17:00:00 ' ,
' 2019 - 10-27 18:00:00 ', ' 2019 - 10-27 19:00:00 ' ,
' 2019 - 10-27 20:00:00 ', ' 2019 - 10-27 21:00:00 ' ,
' 2019 - 10-27 22:00:00 ', ' 2019 - 10-27 23:00:00 ' ] ,
dtype = ' datetime64 [ ns ] ', freq = ' H ' )
date_range()chấp nhận các đối số mà bạn sử dụng để chỉ định bắt đầu hoặc kết thúc phạm vi, số khoảng thời gian, tần suất, múi giờ và hơn thế nữa.
Lưu ý : Mặc dù có những tùy chọn khác, nhưng Pandas hầu hết sử dụng định dạng ngày và giờ ISO 8601 theo mặc định .
Bây giờ bạn đã có những giá trị nhiệt độ và ngày giờ tương ứng, bạn hoàn toàn có thể tạo DataFrame. Trong nhiều trường hợp, thật thuận tiện khi sử dụng những giá trị ngày-giờ làm nhãn hàng :
>> >
>> >temp = pd.DataFrame(data={' temp_c ': temp_c}, index=dt)
>> >temp
temp_c
2019 - 10-27 00:00:00 8.0
2019 - 10-27 01:00:00 7.1
2019 - 10-27 02:00:00 6.8
2019 - 10-27 03:00:00 6.4
2019 - 10-27 04:00:00 6.0
2019 - 10-27 05:00:00 5.4
2019 - 10-27 06:00:00 4.8
2019 - 10-27 07:00:00 5.0
2019 - 10-27 08:00:00 9.1
2019 - 10-27 09:00:00 12.8
2019 - 10-27 10:00:00 15.3
2019 - 10-27 11:00:00 19.1
2019 - 10-27 12:00:00 21.2
2019 - 10-27 13:00:00 22.1
2019 - 10-27 14:00:00 22.4
2019 - 10-27 15:00:00 23.1
2019 - 10-27 16:00:00 21.0
2019 - 10-27 17:00:00 17.9
2019 - 10-27 18:00:00 15.5
2019 - 10-27 19:00:00 14.4
2019 - 10-27 20:00:00 11.9
2019 - 10-27 21:00:00 11.0
2019 - 10-27 22:00:00 10.2
2019 - 10-27 23:00:00 9.1
Đó là nó ! Bạn đã tạo DataFrame với tài liệu chuỗi thời hạn và chỉ số hàng ngày-giờ .
Lập chỉ mục và cắt lát
Khi bạn đã có Pandas DataFrame với tài liệu chuỗi thời hạn, bạn hoàn toàn có thể vận dụng chiêu thức cắt để chỉ lấy một phần thông tin một cách thuận tiện :
>> >
>> >temp[' 2019 - 10-27 05 ':' 2019 - 10-27 14 ']
temp_c
2019 - 10-27 05:00:00 5.4
2019 - 10-27 06:00:00 4.8
2019 - 10-27 07:00:00 5.0
2019 - 10-27 08:00:00 9.1
2019 - 10-27 09:00:00 12.8
2019 - 10-27 10:00:00 15.3
2019 - 10-27 11:00:00 19.1
2019 - 10-27 12:00:00 21.2
2019 - 10-27 13:00:00 22.1
2019 - 10-27 14:00:00 22.4
Ví dụ này cho thấy cách trích xuất nhiệt độ từ 05 : 00 đến 14 : 00 ( 5 giờ sáng và 2 giờ chiều ). Mặc dù bạn đã cung ứng những chuỗi, nhưng Pandas biết rằng những nhãn hàng của bạn là những giá trị ngày-giờ và diễn giải những chuỗi dưới dạng ngày và giờ .
Lấy mẫu lại và cán
Bạn vừa thấy cách tích hợp những nhãn hàng ngày-giờ và sử dụng chiêu thức cắt để lấy thông tin bạn cần từ tài liệu chuỗi thời hạn. Điều này chỉ là khởi đầu. Nó trở nên tốt hơn !
Nếu bạn muốn chia một ngày thành bốn khoảng thời gian sáu giờ và nhận được nhiệt độ trung bình cho mỗi khoảng thời gian, thì bạn chỉ cần thực hiện một tuyên bố. Pandas cung cấp phương pháp .resample()mà bạn có thể kết hợp với các phương pháp khác như .mean():
>> >
>> >temp.resample(rule=' 6 h ').mean( )
temp_c
2019 - 10-27 00:00:00 6.616667
2019 - 10-27 06:00:00 11.016667
2019 - 10-27 12:00:00 21.283333
2019 - 10-27 18:00:00 12.016667
Bây giờ bạn có một Pandas DataFrame mới với bốn hàng. Mỗi hàng tương ứng với một khoảng thời gian sáu giờ. Ví dụ: giá trị 6.616667là giá trị trung bình của sáu nhiệt độ đầu tiên từ DataFrame temp, trong khi giá trị là giá trị trung bình của sáu nhiệt độ 12.016667cuối cùng.
Thay vào đó .mean(), bạn có thể áp dụng .min()hoặc .max()để lấy nhiệt độ tối thiểu và tối đa cho mỗi khoảng thời gian. Bạn cũng có thể sử dụng .sum()để lấy tổng giá trị dữ liệu, mặc dù thông tin này có thể không hữu ích khi bạn đang làm việc với nhiệt độ.
Bạn cũng hoàn toàn có thể cần triển khai một số ít nghiên cứu và phân tích hành lang cửa số luân phiên. Điều này tương quan đến việc giám sát thống kê cho 1 số ít hàng liền kề được chỉ định, tạo nên hành lang cửa số tài liệu của bạn. Bạn hoàn toàn có thể ” cuộn ” hành lang cửa số bằng cách chọn một tập hợp những hàng liền kề khác nhau để triển khai những phép tính của mình .
Cửa sổ tiên phong của bạn khởi đầu với hàng tiên phong trong DataFrame của bạn và gồm có nhiều hàng liền kề như bạn chỉ định. Sau đó, bạn chuyển dời hành lang cửa số của mình xuống một hàng, bỏ hàng tiên phong và thêm hàng đến ngay sau hàng sau cuối và thống kê giám sát lại cùng một thống kê. Bạn lặp lại quy trình này cho đến khi bạn đến hàng sau cuối của DataFrame .
Pandas cung cấp phương pháp .rolling()cho mục đích này:
>> >
>> >temp.rolling(window=3).mean( )
temp_c
2019 - 10-27 00:00:00 NaN
2019 - 10-27 01:00:00 NaN
2019 - 10-27 02:00:00 7.300000
2019 - 10-27 03:00:00 6.766667
2019 - 10-27 04:00:00 6.400000
2019 - 10-27 05:00:00 5.933333
2019 - 10-27 06:00:00 5.400000
2019 - 10-27 07:00:00 5.066667
2019 - 10-27 08:00:00 6.300000
2019 - 10-27 09:00:00 8.966667
2019 - 10-27 10:00:00 12.400000
2019 - 10-27 11:00:00 15.733333
2019 - 10-27 12:00:00 18.533333
2019 - 10-27 13:00:00 20.800000
2019 - 10-27 14:00:00 21.900000
2019 - 10-27 15:00:00 22.533333
2019 - 10-27 16:00:00 22.166667
2019 - 10-27 17:00:00 20.666667
2019 - 10-27 18:00:00 18.133333
2019 - 10-27 19:00:00 15.933333
2019 - 10-27 20:00:00 13.933333
2019 - 10-27 21:00:00 12.433333
2019 - 10-27 22:00:00 11.033333
2019 - 10-27 23:00:00 10.100000
Bây giờ bạn có DataFrame với nhiệt độ trung bình được tính toán cho một số cửa sổ ba giờ. Tham số windowchỉ định kích thước của cửa sổ thời gian di chuyển.
Trong ví dụ trên, giá trị thứ ba ( 7.3) là nhiệt độ trung bình trong ba giờ đầu tiên ( 00:00:00, 01:00:00và 02:00:00). Giá trị thứ tư là nhiệt độ trung bình cho giờ 02:00:00, 03:00:00và 04:00:00. Giá trị cuối cùng là nhiệt độ trung bình trong ba giờ qua, 21:00:00, 22:00:00, và 23:00:00. Hai giá trị đầu tiên bị thiếu vì không có đủ dữ liệu để tính toán chúng.
Lập kế hoạch với dữ liệu gấu trúc
Pandas được cho phép bạn trực quan hóa dữ liệu hoặc tạo những lô dựa trên DataFrames. Nó sử dụng Matplotlib ở chính sách nền, thế cho nên việc khai thác năng lực thủ đoạn của Pandas rất giống với thao tác với Matplotlib .
Nếu bạn muốn hiển thị các ô, thì trước tiên bạn cần nhập matplotlib.pyplot:
>> >
>> >import matplotlib.pyplot as plt
Bây giờ bạn có thể sử dụng pandas.DataFrame.plot()để tạo cốt truyện và plt.show()hiển thị nó:
>> >
>> >temp.plot( )
>> >plt.show( )
Bây giờ .plot()trả về một plotđối tượng trông giống như sau:
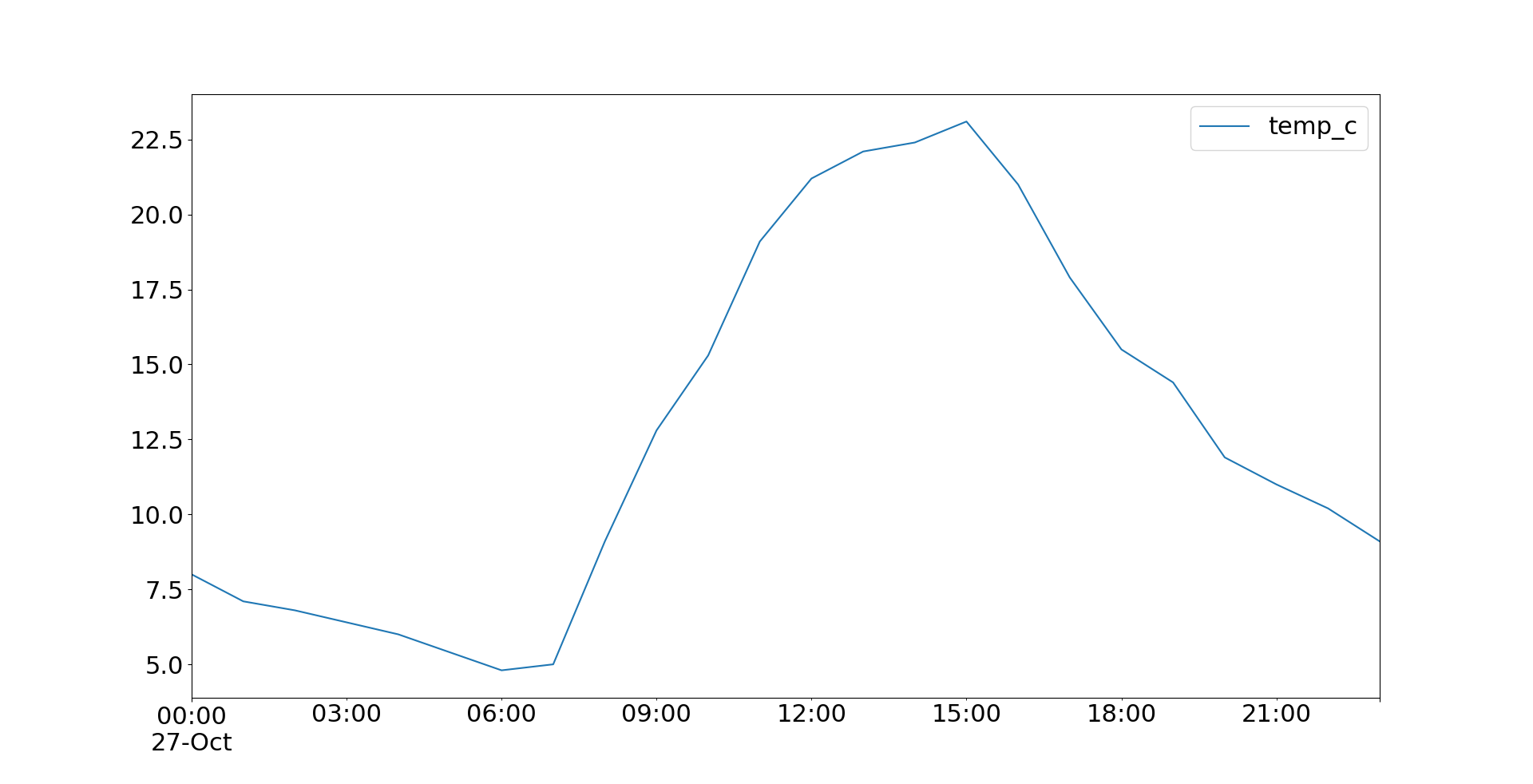
Bạn cũng có thể áp dụng .plot.line()và nhận được kết quả tương tự. Cả hai .plot()và .plot.line()có nhiều tham số tùy chọn mà bạn có thể sử dụng để chỉ định giao diện của âm mưu của bạn. Một số trong số chúng được chuyển trực tiếp đến các phương thức Matplotlib cơ bản.
Bạn có thể lưu hình của mình bằng cách xâu chuỗi các phương pháp .get_figure()và .savefig():
>> >
>> >temp.plot( ).get_figure( ).savefig(' temperatures.png ')
Câu lệnh này tạo cốt truyện và lưu nó dưới dạng tệp được gọi 'temperatures.png'trong thư mục làm việc của bạn.
Bạn có thể lấy các loại ô khác bằng Pandas DataFrame. Ví dụ: bạn có thể hình dung dữ liệu ứng viên công việc của mình từ trước đó dưới dạng biểu đồ với .plot.hist():
>> >
>> >df.loc[ :, [' py-score ', ' total '] ].plot.hist(bins=5, alpha=0.4)
>> >plt.show( )
Trong ví dụ này, bạn trích xuất dữ liệu điểm và tổng điểm của bài kiểm tra Python và trực quan hóa nó bằng biểu đồ. Cốt truyện tác dụng trông như thế này :
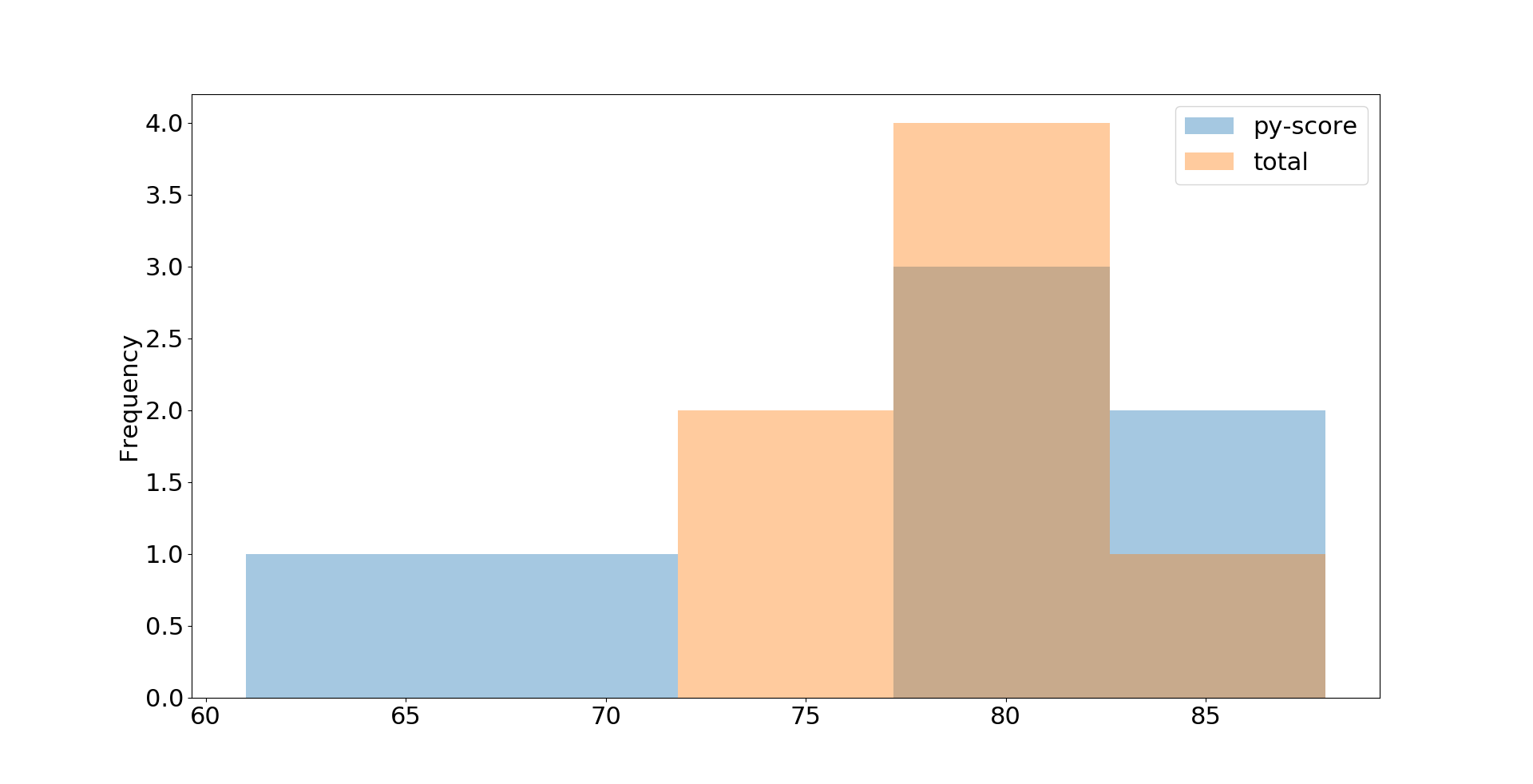
Đây chỉ là cái nhìn cơ bản. Bạn có thể điều chỉnh chi tiết với các thông số tùy chọn bao gồm .plot.hist(), Matplotlib’splt.rcParams , và nhiều thông số khác. Bạn có thể tìm thấy những lời giải thích chi tiết trong Anatomy of Matplotlib .
Đọc thêm
Pandas DataFrames là những đối tượng người tiêu dùng rất tổng lực tương hỗ nhiều thao tác không được đề cập trong hướng dẫn này. Một số trong số này gồm có :
Các quan chức Pandas hướng dẫn tóm tắt 1 số ít những tùy chọn có sẵn độc lạ. Nếu bạn muốn khám phá thêm về Pandas và DataFrames, thì bạn hoàn toàn có thể xem những hướng dẫn sau :
Bạn đã biết rằng Pandas DataFrames giải quyết và xử lý tài liệu hai chiều. Nếu bạn cần thao tác với tài liệu được gắn nhãn trong nhiều hơn hai chiều, bạn hoàn toàn có thể xem xarray, một thư viện Python can đảm và mạnh mẽ khác dành cho khoa học dữ liệu với những tính năng rất giống với Pandas .
Nếu bạn thao tác với tài liệu lớn và muốn có thưởng thức giống như DataFrame, thì bạn hoàn toàn có thể cho Dask một thời cơ và sử dụng API DataFrame của nó. Một Dask DataFrame chứa nhiều Pandas DataFrame và thực thi giám sát một cách lười biếng .
Phần kết luận
Bây giờ bạn đã biết Pandas DataFrame là gì, một số tính năng của nó và cách bạn có thể sử dụng nó để làm việc với dữ liệu một cách hiệu quả. Pandas DataFrames là cấu trúc dữ liệu mạnh mẽ, thân thiện với người dùng mà bạn có thể sử dụng để hiểu sâu hơn về tập dữ liệu của mình!
Xem thêm: Kiểu dữ liệu số trong Python | How Kteam
Trong hướng dẫn này, bạn đã học được :
- Pandas DataFrame là gì và cách tạo một Pandas DataFrame
- Cách truy cập, sửa đổi, thêm, sắp xếp, lọc và xóa dữ liệu
- Cách sử dụng quy trình NumPy với DataFrames
- Cách xử lý các giá trị bị thiếu
- Cách làm việc với dữ liệu chuỗi thời gian
- Cách trực quan hóa dữ liệu có trong DataFrames
Bạn đã học đủ để bao quát những nguyên tắc cơ bản của DataFrames. Nếu bạn muốn khám phá sâu hơn về cách thao tác với tài liệu bằng Python, hãy xem hàng loạt những hướng dẫn về Gấu trúc .
Nếu bạn có vướng mắc hoặc quan điểm góp phần, thì hãy để chúng ở phần phản hồi bên dưới.
Source: https://final-blade.com
Category: Kiến thức Internet